OSINT-Collector is an advanced framework that facilitates the collection, analysis, and management of OSINT information useful for conducting investigations in specific domains of interest.
- Design and Architecture
- Requirements
- Sequence Diagram
- Backend
- Launcher
- Frontend
- Usage
- Preventing a School Shooting: a DEMO Scenario!

In this framework has been used an Ontology approach:
- The OSINT Ontology describes how data extracted from OSINT sources should be inserted into the database, including their respective properties and relationships.
- Domain Ontologies describe various domains of interest. These ontologies are utilized to link the extracted data to entities within these domains, enabling deeper inferences.
Using the graphical interface, the user can select an OSINT tool, input required parameters, and initiate execution to perform a specific search. This execution request is sent via an HTTP request to the Launcher, which then executes the requested tools using the corresponding inputs. The resulting data are aggregated, filtered and sent via an HTTP request to the backend, which communicates with the database and performs the following operations:
- Insertion and linking of data based on the schema described by the OSINT Ontology.
- Analysis of textual documents using NLP techniques provided by cloud services to extract suspicious entities and moderate the text to identify dangerous categories.
- Linking of entities and categories extracted in the previous phase with the domain ontologies.
The user can visualize the search results through the graphical interface, with the framework highlighting the identified contents during the analysis, emphasizing suspicious entities and categories. Users can conduct further, more in-depth searches.
Using the OSINT Ontology allows for easily including new OSINT sources to leverage.
This project requires the following dependencies to be installed:
- Docker and Docker Compose
- Node.js and npm
Before proceeding to the configuration of the frameworks, it is crucial to delve into detail and describe how the various components of the framework communicate and interact with each other. This sequence diagram illustrates in detail how our framework manages to obtain, filter, save, and process OSINT informations. In this example, the user requests the framework to download all messages sent within a Telegram group.
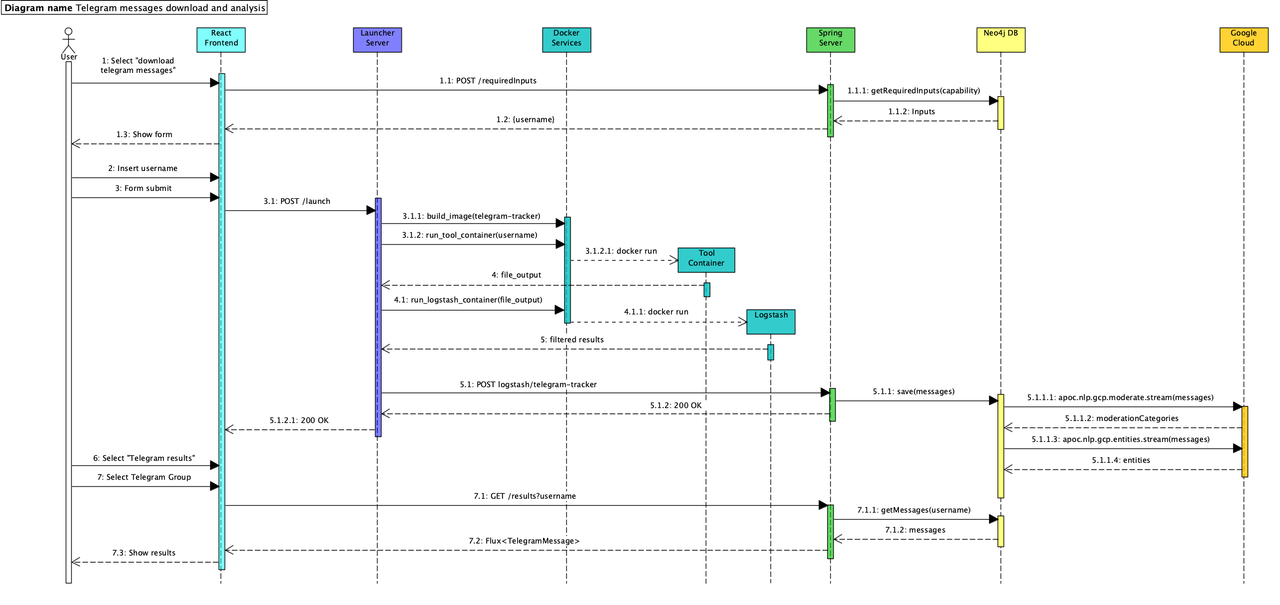
1. Tool Selection:
- The user selects the desired tool through the graphical interface based on the available capabilities. For instance, the user might choose "download telegram messages".
- The frontend then sends a POST request to the Spring server to determine the required inputs for executing the chosen tool.
2. Input Provisioning:
- The server queries the database and returns the result to the frontend, which displays a form where the user must enter the required inputs. For example, the user might be prompted to enter the "username" of the Telegram group to analyze.
3. Tool Execution:
- The user enters the necessary inputs, such as the Telegram group username (e.g., "@osintcollector_group").
- Upon clicking the "launch" button, the frontend sends a POST request to the launcher containing the tool and its respective inputs.
- The launcher then builds a Docker container using the tool image and launches it with the corresponding command (e.g., using the "telegram-tracker" image).
4. Output Processing:
- The container generates an output file containing all the messages downloaded from the Telegram group and sends it to the launcher.
- The launcher initiates and starts the Logstash container, which processes the output file obtained in the previous step.
- Logstash filters and refines the data, producing a new file containing the results of the tool, and sends it to the Spring server.
5. Data Storage and Analysis:
- The Spring server saves all the messages to the database along with their respective relationships and properties through queries.
- The database asynchronously analyzes the textual part of these messages by making requests to the Google Cloud APIs. These APIs return moderation categories and entities, which are then linked in the graph to their respective messages.
6. Accessing Results:
- The user can access the results by clicking on the "Telegram results" section.
- They can select the recently analyzed username from the list, and the frontend sends a request to the Spring server to retrieve all messages from the database.
- The frontend then displays the messages in a structured manner, highlighting all the information obtained and extracted in the previous steps.
This interaction pattern repeats every time a new OSINT search is initiated by the user, utilizing the available tools within the framework.
Clone the project
git clone https://github.com/NS-unina/OSINT-Collector.gitGo to the project directory
cd OSINT-CollectorGo to the backend directory
cd Backend/OSINT-CollectorUse docker-compose to start the Spring Server and Neo4j Database
docker-compose up -dAccess the Web UI at http://localhost:7474/ with the following credentials:
- Username: "neo4j"
- Password: "password"
Create uniqueness constraint; in RDF everything is uniquely identified by URI. And the way to store it efficiently in Neo4j is by creating an index (a constraint) that guarantees both the uniqueness, but also gives a fast access to it.
CREATE CONSTRAINT n10s_unique_uri ON (r:Resource) ASSERT r.uri IS UNIQUE;Setting the configuration of the graph; with this option we can map the Ontolgy URIs with custom names, more human readble.
CALL n10s.graphconfig.init({handleVocabUris: "MAP"});The method n10s.graphconfig.init() can help us initialising the Graph Config. Calling the procedure without parameters will set all the default values.
CALL n10s.nsprefixes.add('osint','osint://voc#');
CALL n10s.mapping.add("osint://voc#subCatOf","SUB_CAT_OF");
CALL n10s.mapping.add("osint://voc#about","ABOUT");Ontologies are serialised as RDF, so they can be imported using plain n10s.rdf.import.fetch but the n10s.onto.import.fetch method will give us a higher level of control over how an RDFS or OWL ontology is imported into Neo4j. So with the following command we can import the OSINT Ontolgy:
CALL n10s.onto.import.fetch("https://raw.githubusercontent.com/ciro-99/OSINT/main/osint%20ontology/OSINT_v6.2.ttl","Turtle")To see a preview of the ontology without importing it, use the following function:
CALL n10s.onto.preview.fetch("https://raw.githubusercontent.com/ciro-99/OSINT/main/osint%20ontology/OSINT_v6.2.ttl","Turtle")In our case, the OSINT Ontology specifically describes which entities can be extracted from social networks, what their properties are, and how they interconnect with each other. The social networks of interest are as follows: X (formerly Twitter), Telegram, and Instagram:

In this section, we will explain how it is possible to define domain ontologies to extract information related to domains of interest. In this case, we will demonstrate how to create an ontology to define and classify firearms. This approach allows us to extract only entities of interest and, importantly, to obtain an interconnected graph with the ontology for conducting semantic searches or inferences.
Wikidata is a free and open knowledge base that can be read and edited by both humans and machines. It acts as central storage for the structured data of its Wikimedia sister projects including Wikipedia. Wikidata stores data as RDF and offers a SPARQL API (https://query.wikidata.org/; we can write a query and convert the results to an RDF endpoint. Wikidata classes are identified with a unique alphanumeric code that can be referenced within the query.
The query below extracts all categories that are subclasses or instances of the "weapons" class (Q728); this logic is iterated for all items identified in the first iteration. This query is valuable for extracting hierarchical information about a specific category (in this case, wd:Q728) and any related Wikipedia articles in Italian or any other languages; you simply need to replace the language code from "it" to, for example, "en".

We can create other ontologies simply changing the class code. For exampe if we want to create a Drug Ontology, we can replace the code with "Q8386". At this point we can import the Wikidata’s Ontolgies into Neo4j, using the SPARQL Endpoint URI:

WITH "<SPARQL Endpoint>" AS uri
CALL n10s.rdf.import.fetch(uri, 'Turtle' , { headerParams: { Accept: "application/x-turtle" } })
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, callParams;At this point, it is necessary to remove the n10s plugin and install the APOC plugin to enable NLP methods.
rm neo4j/plugins/n10s.jar cp ../../APOC/apo.jar neo4j/plugins
cp ../../APOC/apoc-nlp-dependencies.jar neo4j/pluginsThen restart the docker containers:
docker-compose restartGo to the Launcher directory
cd ../../Launcher/Run the Launcher with:
docker-compose up -dMore details available at: Launcher README
Go to the frontend directory
cd ../Frontend/OSINT-CollectorInstall dependencies:
npm installRun the frontend with:
npm run devThe WebUI can be accessed locally at: http://127.0.0.1:5173/
By clicking the tool switch in the top right of the web interface, you can access the section for technical users where you can add or remove OSINT tools. To do this, you can use the YAML files located in the directory "OSINT-Collector/Frontend/OSINT-Collector/Tools".
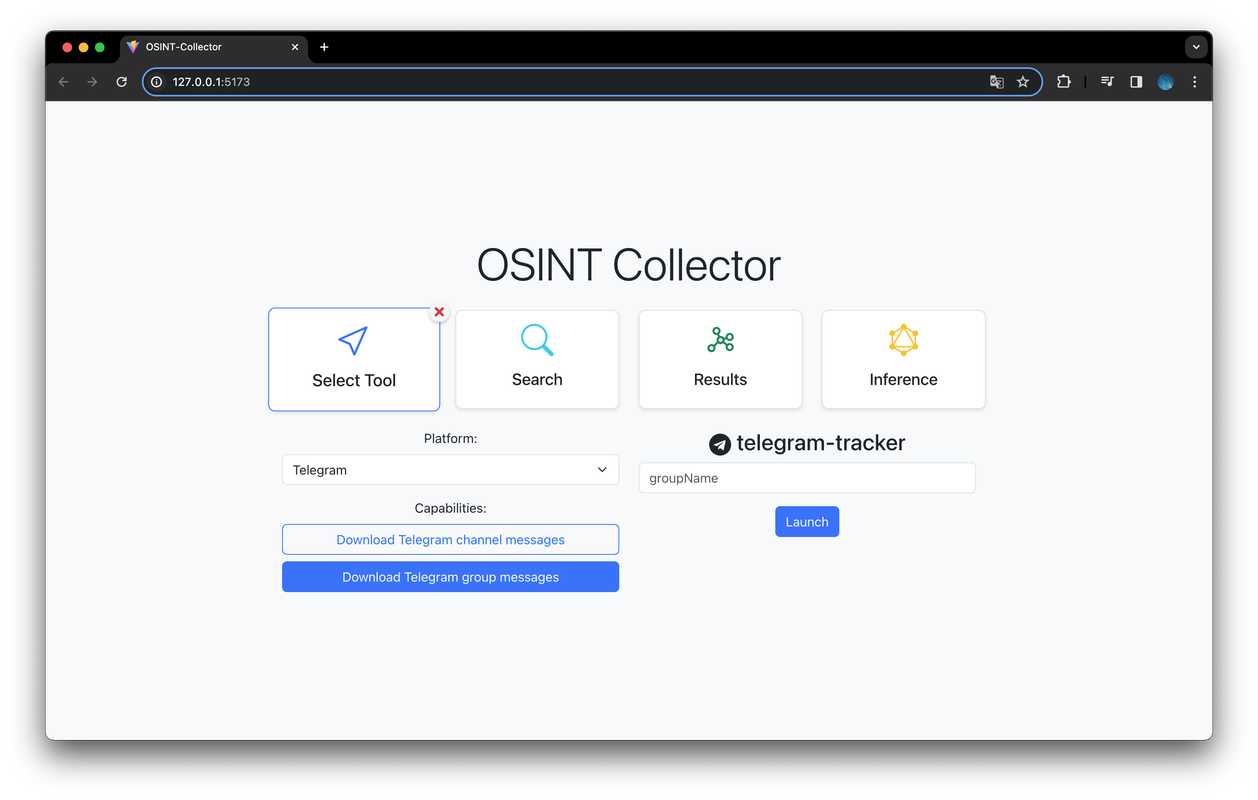
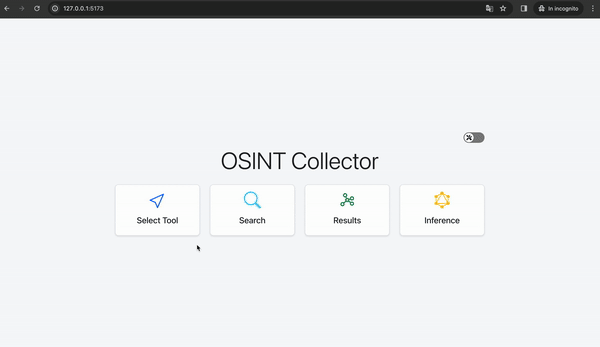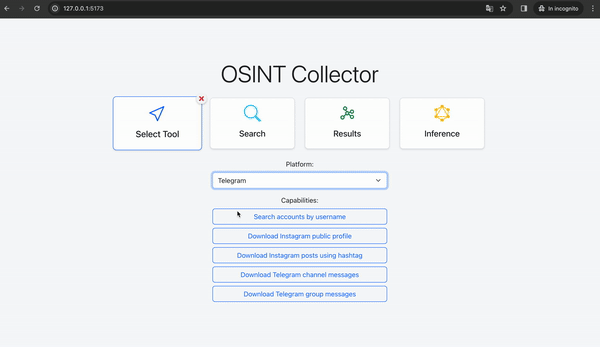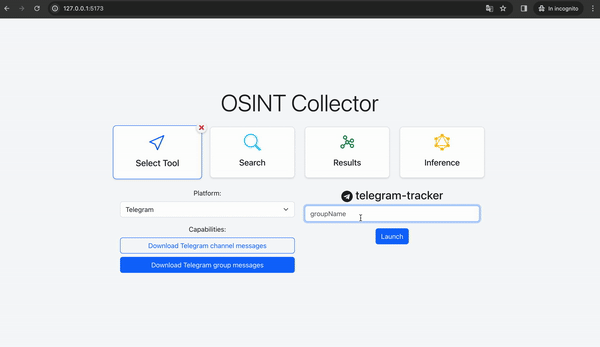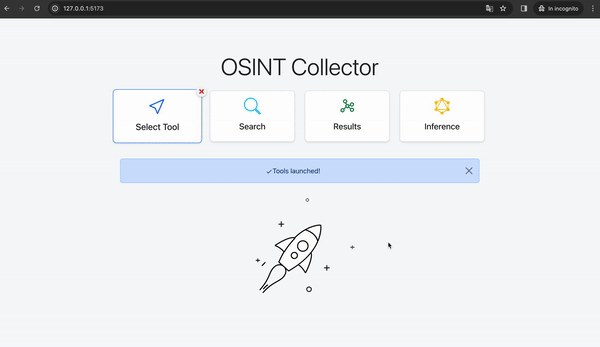
The selection view presents a comprehensive list of all the capabilities offered by the tools within the system. Furthermore, it features a dropdown menu that enables users to filter the capabilities based on social media platforms. The frontend renders a form allowing users to input the required data and launch the selected tools.
When the tool is launched, a POST request is sent to the Launcher to execute the tools with their respective inputs. Once the results are ready, they can be viewed in the results section.
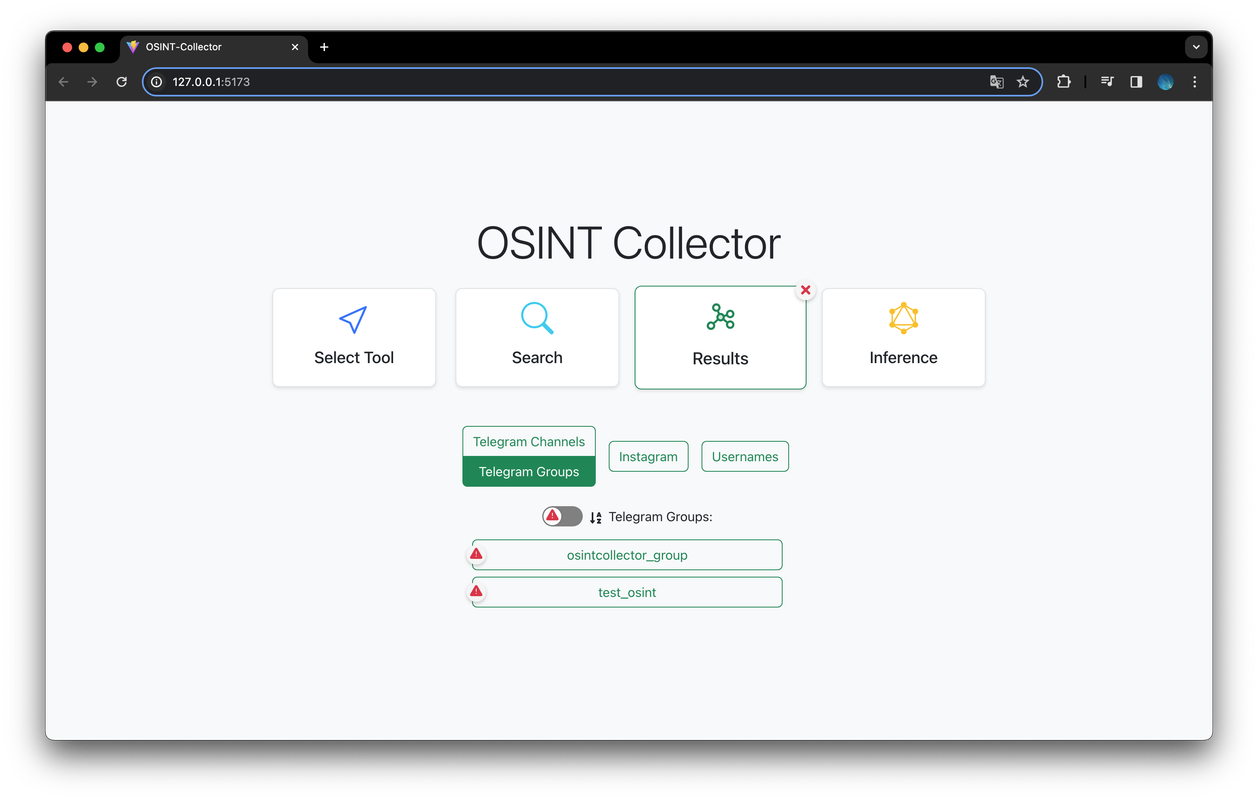
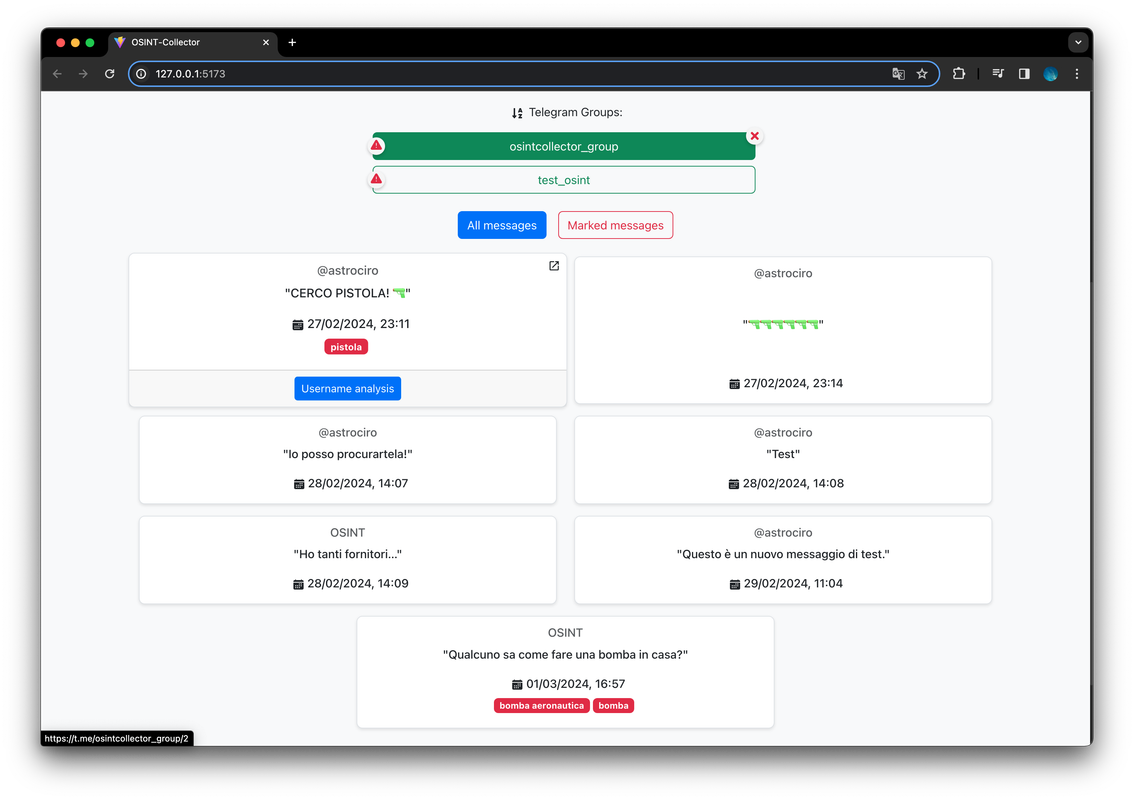
The results are grouped into macro-categories. When one of these categories is clicked, a list of entities analyzed is displayed along with some preliminary visual information. If during the analysis on the backend, the entity has been flagged, a danger icon is shown to distinguish the hazardous results from the others. There is also a switch that allows you to display only flagged entities and a button to sort the entities alphabetically.
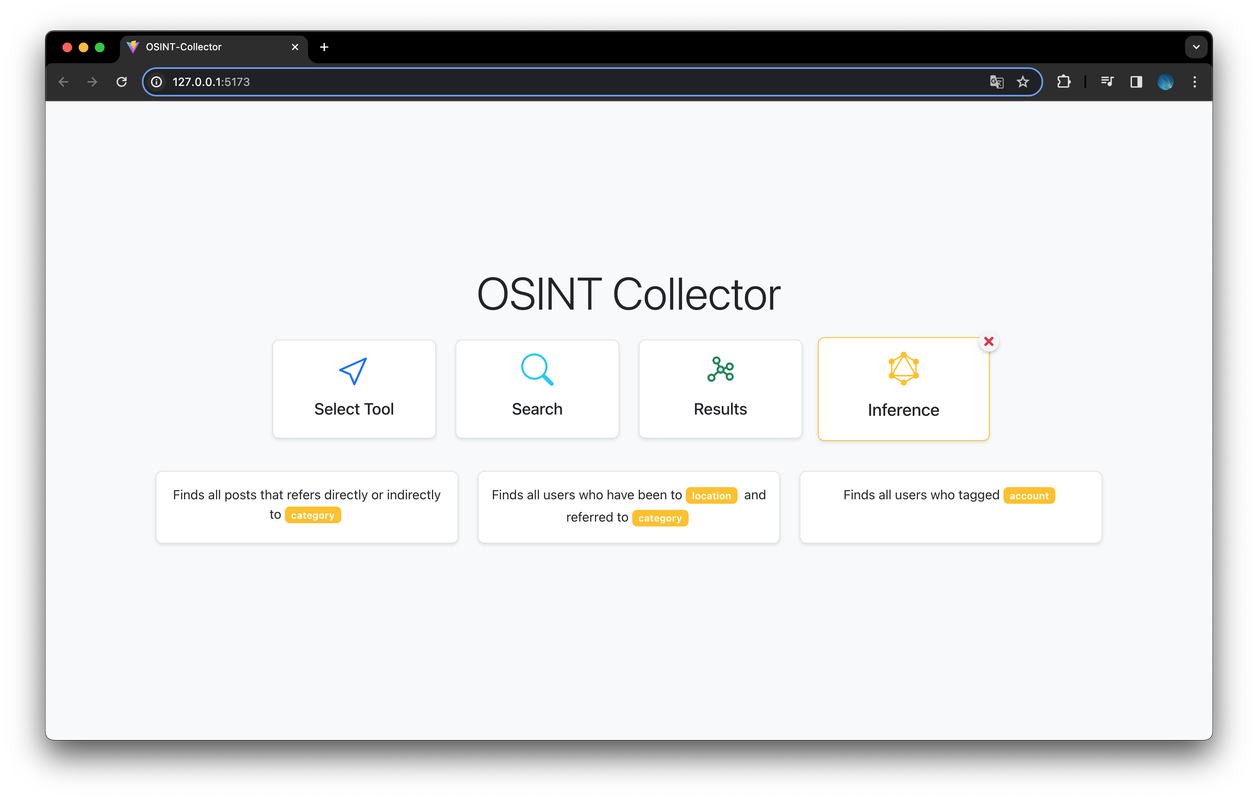
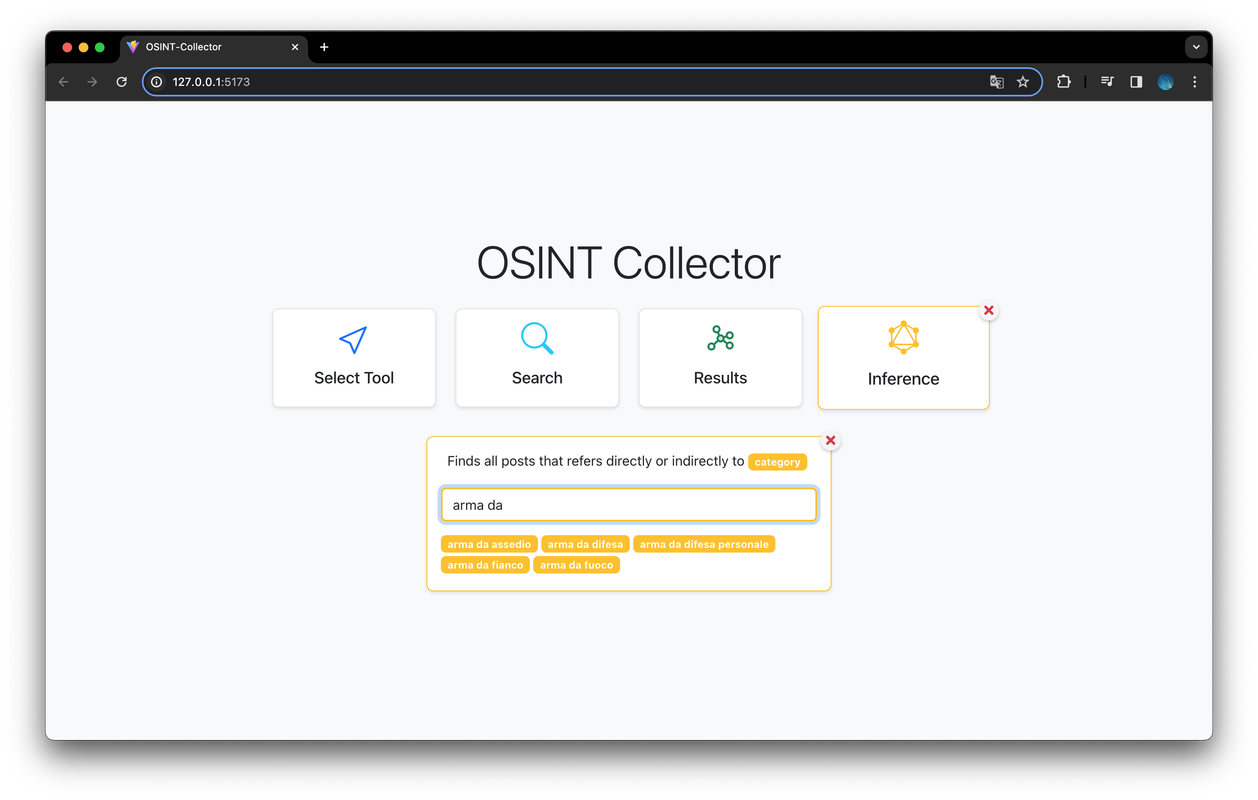
Through the Inference view users can select from some preset queries to conduct in-depth inferences on all the collected data. When clicking on one of the inferences to be made, the user is guided in building the query, with inputs suggested based on the data present in the database. Queries are sent to the server and converted into actual Cypher queries to obtain the desired results.
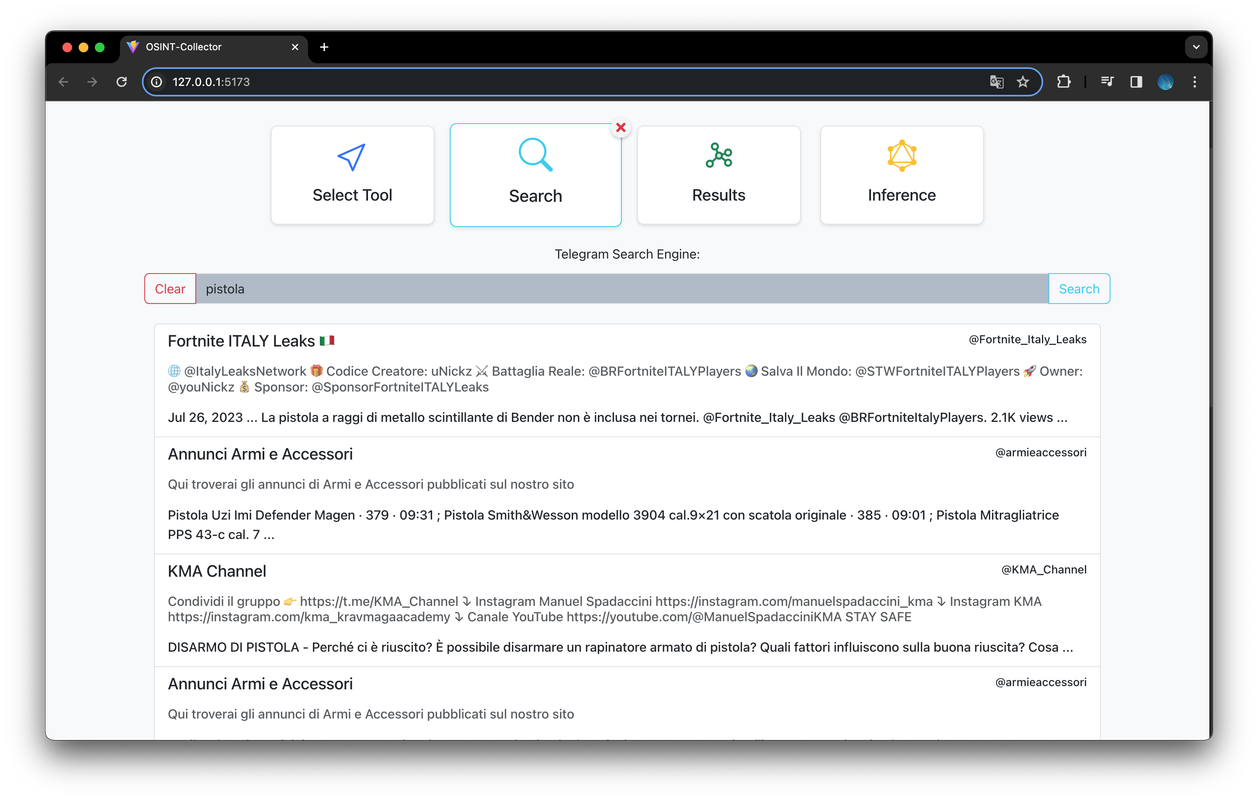
Within the "Search" section, there is a search bar that allows users to conduct searches related to Telegram channels, bots, or groups using an API to retrieve search results from Google's Custom Search Engine (CSE). This tool, provided by Google, enables website owners to create a customized search experience for their users. With CSE, website owners can specify particular websites or pages to include in the search index, allowing users to search within a curated set of content.
«I introduce myself, my name is David, and I want to carry out a shooting at school and possibly commit suicide...»
With this Telegram message, David Kozak, the perpetrator of the University of Prague shooting in December 2023, expressed his intent to carry out a school shooting and potentially commit suicide. This real-life incident has inspired our demonstration scenario.
This scenario demonstrates how our framework can be used to identify and counter potential similar threats.
Using the Search Engine, we attempted to locate Telegram groups discussing weapon purchases, focusing on keywords related to the firearm used in the Prague incident.
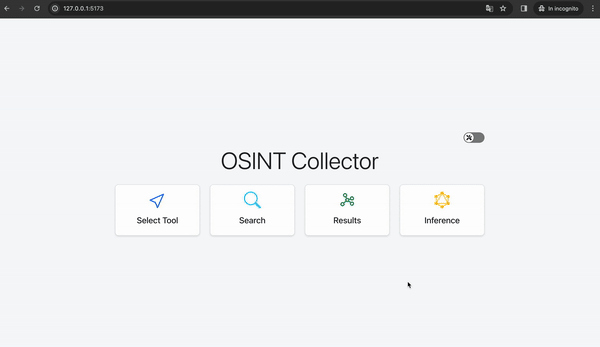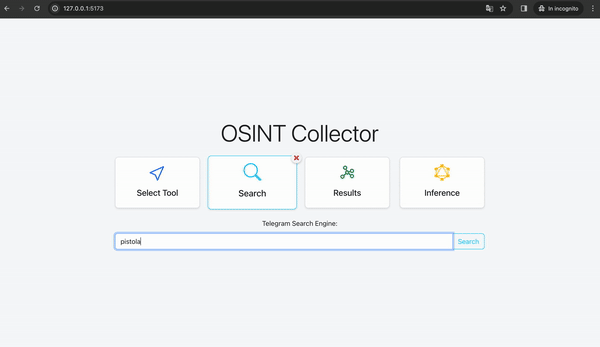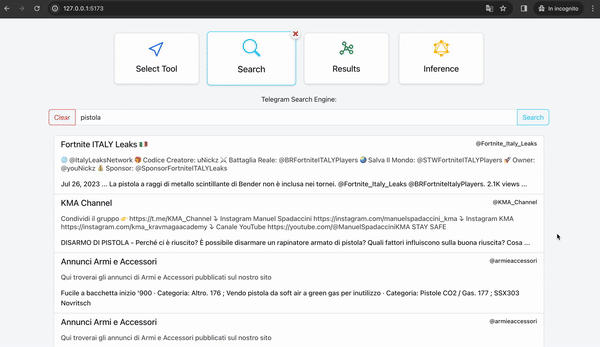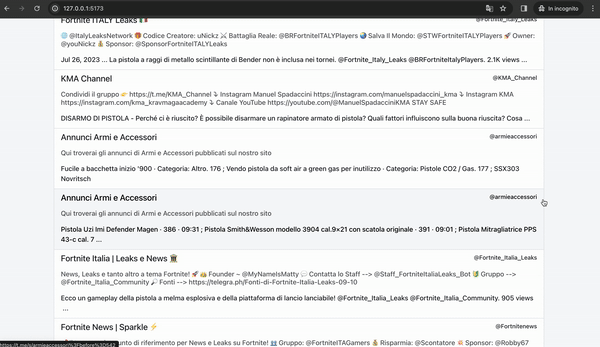
We can retrieve the group's username and proceed with further investigations. Subsequently, we can utilize a tool to gather all messages exchanged within the "@osintcollector_group" and scrutinize them for any suspicious content, focusing particularly on identifying the senders.
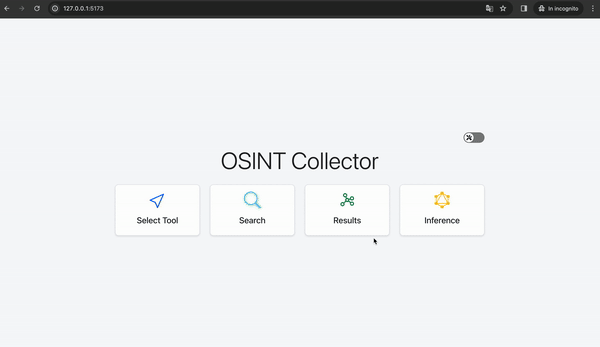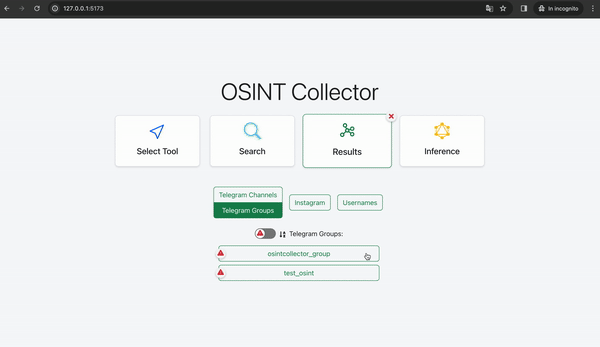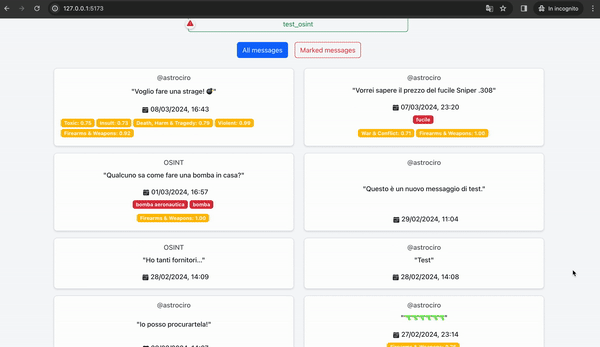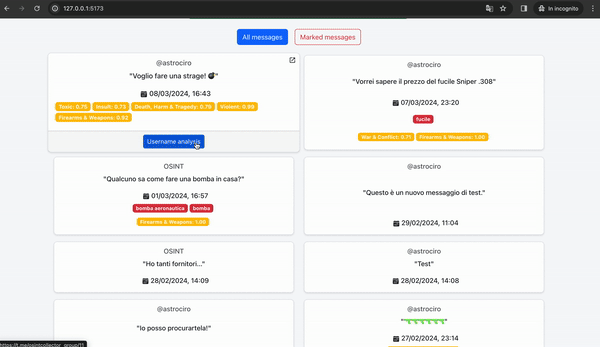
Thus, we have identified the first possible dangerous individual who intends to acquire firearms and use them in a dangerous manner. Our framework also provides us with the sender's username, which we can use once again to conduct further investigations. The framework allows us to start a comprehensive search of the username on different websites and social networks directly from the results dashboard by clicking on the "username analysis" button.
We can observe the results obtained by analyzing the username. Among the various results, we can notice that the same username is associated with a Facebook profile and also an Instagram profile, which was promptly analyzed automatically by our framework. Then we can then check the results obtained from this analysis.
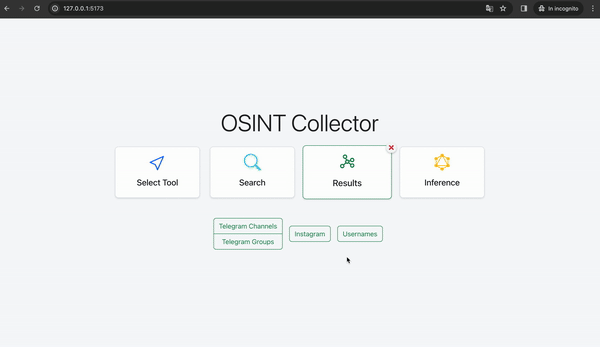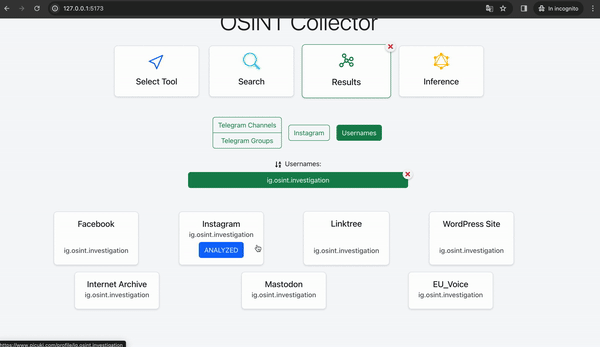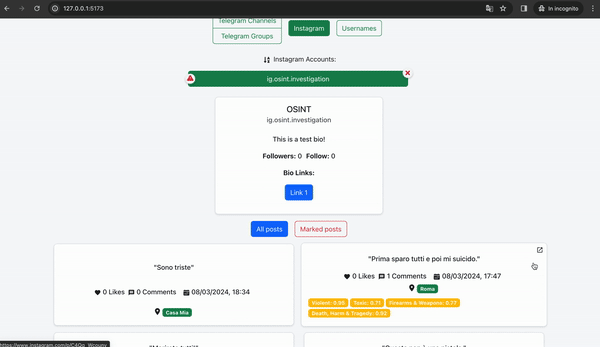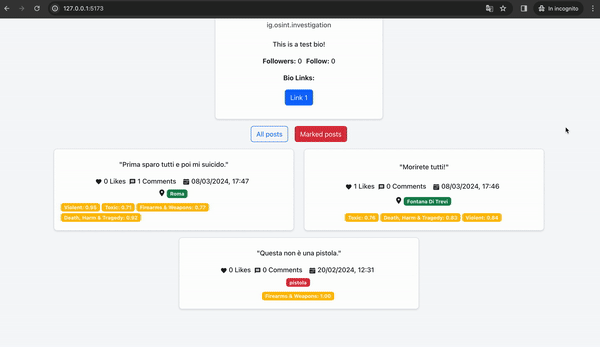
By filtering the marked posts, we can immediately notice that once again, the NLP system has identified several potentially dangerous posts. In particular, the last posts published by this individual are very concerning, referring to death and massacres. There is no doubt that this individual is a potential terrorist and must be stopped as soon as possible. The results provide us with another important clue: the geolocation of the posts.
With these results obtained, the armed forces can intervene cautiously by issuing a possible terrorism alert to try to prevent the worst.