Designing good, original kitting is a surprisingly difficult problem. In particular, we require that:
- Common keyboards are covered
- Individual kits are reasonably small so they may be offered relatively cheaply
- A particular customer should not be expected to require too many kits
- The overall number of kits is not absurdly high
- The assignment of keys into kits makes sense to fellow humans.
What we have, therefore, is a fundamentally-human problem which contains parts which require a large amount of repetitive work.
Therefore, I wrote this script to give the keycap designer a hand by analysing their kitting choices in response to a set of keyboard layouts to cover. These characteristics should help give an idea of how kitting will be perceived and used by (rational) potential customers.
KeyCov can’t kit, but it can give the designer some peace-of-mind in their existing decisions and hence smoothen the path to novel and creative kitting solutions, well-tailored to their set.
You’ll need a working installation of python3 and its package manager pip3.
Download and unzip the latest release then open up a terminal and type the following commands.
(These assume that the archive was unzipped in ~/Downloads/keycov/.)
cd ~/Downloads/keycov/
pip3 install -r requirements.txt
python3 keycov.py --helpA message detailing the usage of KeyCov should now be visible, like the one below.
usage: keycov.py [-C] [-c] [-f format] [-h] [-H] [-k dir] [-l dir] [-L num]
[-t theme] [-v level]
A little script for helping keycap designers analyse kitting coverage
optional arguments:
-C, --colour Force colour output (override default heuristics)
(default: False)
-c, --no-colour Force no colour output (override default heuristics)
(default: False)
...
Before running, KeyCov will require two things:
- A folder containing the keyboards the user wishes to support (in KLE format).
- A folder containing the kits the user proposes for their set (in KLE format)
To run KeyCov, open a terminal and type the following (assuming that the latest release was unzipped to ~/Downloads/keycov/).
cd ~/Downloads/keycov/
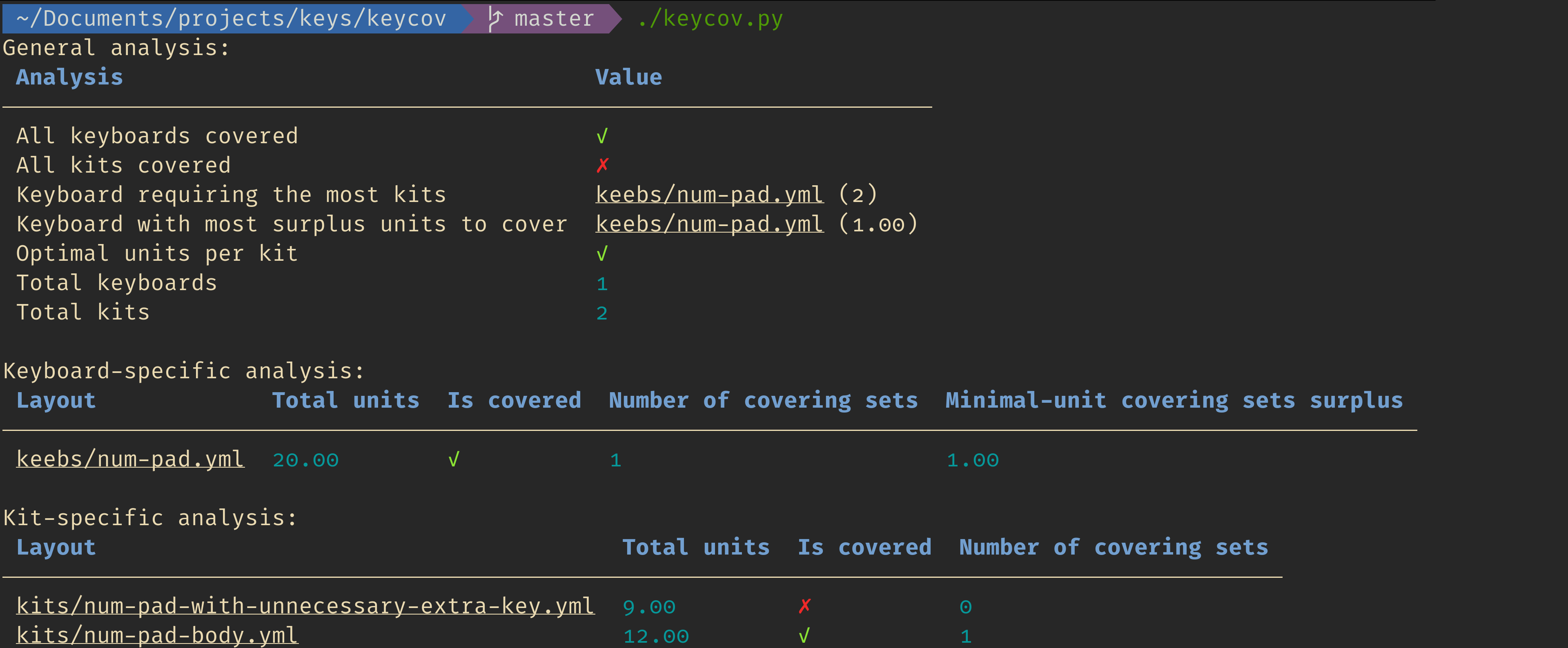
python3 keycov.pyThis will output a basic set of analyses; KeyCov defaults to analysis-verbosity level 1.
For more information, pass a higher verbosity number by running something like python3 keycov.py --analysis-verbosity=3
Details on the analyses performed and the verbosity levels required to output them are shown by passing KeyCov the --long-help flag.
Aside from text, KeyCov supports json and yaml output formats to allow an interface with a more customer-friendly front-end (e.g a keycap set website).
There is also a python API which can be accessed through the keycov function in src.keycov_main which takes a dictionaries with keys specified by the dest field in entry in src.args.args.
If running on Linux or macOS, it is possible to make the python3 command above somewhat shorter by downloading the keycov binary from the latest release and replacing the python3 keycov.py above with ./keycov.
The file ./keycov is just a zip archive of the source which can be run by python anywhere (assuming it can access its dependencies).
Building and running from the source has the same requirements as general setup, with the addition of git, make and pipreqs (only required to make a distributable) as well as some standard UNIX applications.
The build system has been tested on Linux, although it’s quite simple and shouldn’t be too much of a problem to get working on MacOS or Windows with help from Gow or something.
To download and build the code, run:
cd Downloads/
git clone https://www.github.com/TheSignPainter98/keycov
cd keycov
makeThe code should now be runnable in the usual way.
To remove any files generated by previous builds, run:
make cleanTo build a distributable version of the code, run:
make distContributions are welcome! If you’d like to contribute, please abide by the code of conduct.
This code was written by Ed Jones (Discord @kcza#4691).
Please don’t be surprised if KeyCov takes a while to perform its analyses, with many input layouts, there is an exponentially-large number of states which must be checked in order to return accurate results.
There is an option to speed up the analysis (-q/--quick-coverage-analysis) by not considering the kits chosen in reaching a certain coverage-point, but some caution is advised.
When used, the result for whether there exists a covering set is still guaranteed to be correct, but the number of covering sets becomes a lower-bound, and the size of the smallest covering set becomes an upper-bound as some possibilities can be disregarded.
This faster version can still take one time, but at this point the problem of finding a more efficient algorithm becomes a fundamental one. The problem now considered is exactly set cover, a standard problem in theoretical computer science for which:
- We do not know of an algorithm which runs in less-than exponential time and,
- We do not know whether one can or cannot exist on our classical hardware.