diff --git a/docs/lineage/airflow.md b/docs/lineage/airflow.md
index f0952309c328a..1745c23cb1923 100644
--- a/docs/lineage/airflow.md
+++ b/docs/lineage/airflow.md
@@ -69,7 +69,7 @@ enabled = True # default
| -------------------------- | -------------------- | ---------------------------------------------------------------------------------------- |
| enabled | true | If the plugin should be enabled. |
| conn_id | datahub_rest_default | The name of the datahub rest connection. |
-| cluster | prod | name of the airflow cluster |
+| cluster | prod | name of the airflow cluster, this is equivalent to the `env` of the instance |
| capture_ownership_info | true | Extract DAG ownership. |
| capture_tags_info | true | Extract DAG tags. |
| capture_executions | true | Extract task runs and success/failure statuses. This will show up in DataHub "Runs" tab. |
diff --git a/docs/managed-datahub/subscription-and-notification.md b/docs/managed-datahub/subscription-and-notification.md
index b30a03de16511..04be0ca1c719e 100644
--- a/docs/managed-datahub/subscription-and-notification.md
+++ b/docs/managed-datahub/subscription-and-notification.md
@@ -93,6 +93,39 @@ You can view and manage the group’s subscriptions on the group’s page on Dat
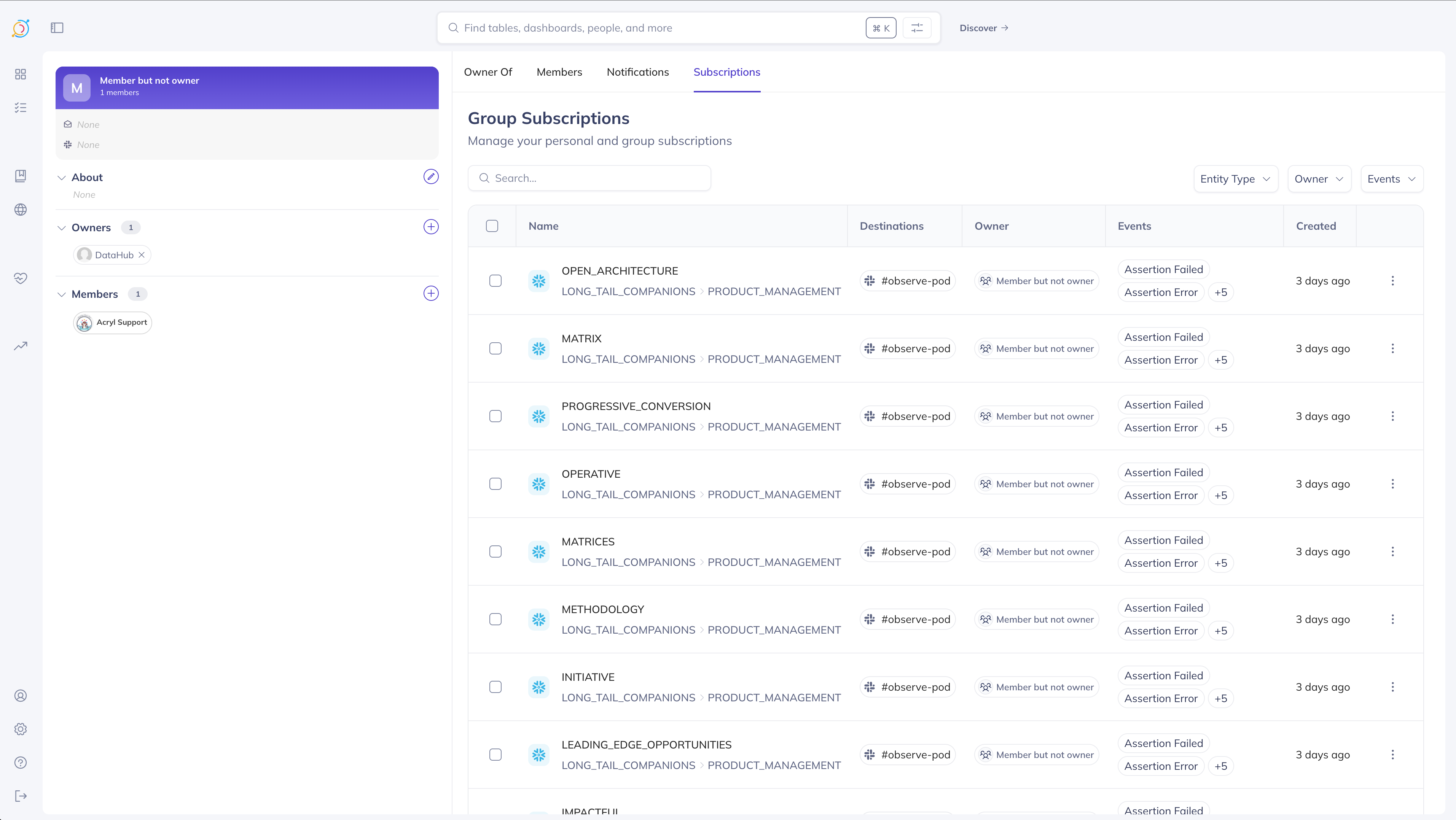 +### Subscribing to Assertions
+You can always subscribe to _all assertion status changes_ on a table using the steps outlined in the earlier sections. However, in some cases you may want to only be notified about specific assertions on a table. For instance, a table may contain several subsets of information, segmented by a category column - so there may be several different checks for each category. As a consumer, you may only care about the freshness check that runs on one specific category of this larger table.
+
+You can subscribe to individual assertions by clicking the bell button on the assertion itself - either in the list view:
+
+### Subscribing to Assertions
+You can always subscribe to _all assertion status changes_ on a table using the steps outlined in the earlier sections. However, in some cases you may want to only be notified about specific assertions on a table. For instance, a table may contain several subsets of information, segmented by a category column - so there may be several different checks for each category. As a consumer, you may only care about the freshness check that runs on one specific category of this larger table.
+
+You can subscribe to individual assertions by clicking the bell button on the assertion itself - either in the list view:
+
+  +
+
+
+Or on the assertion's profile page:
+
+ 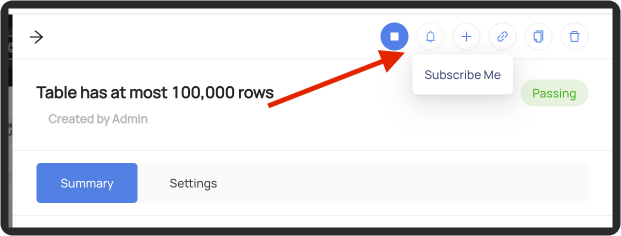 +
+
+
+
+Note: if you are subscribed to all assertions at the dataset level, then you will not be able to **Unsubscribe** from an individual assertion.
+
+ 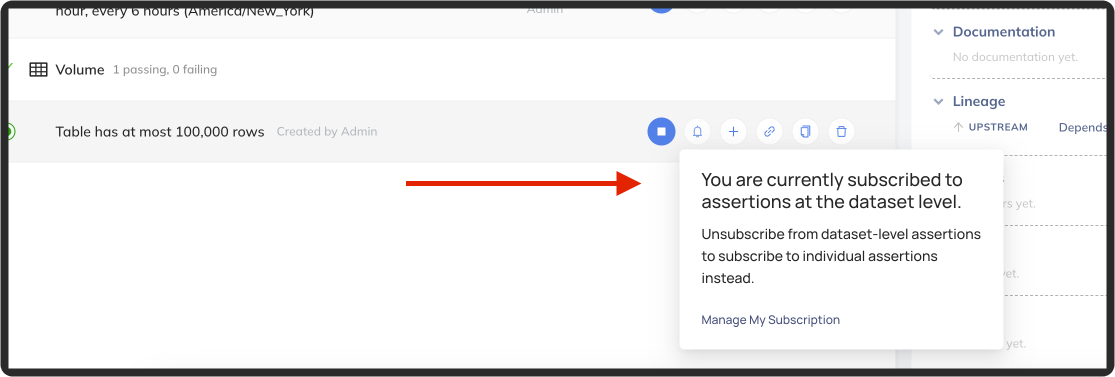 +
+
+
+You must first remove your dataset-level subscription:
+
+ 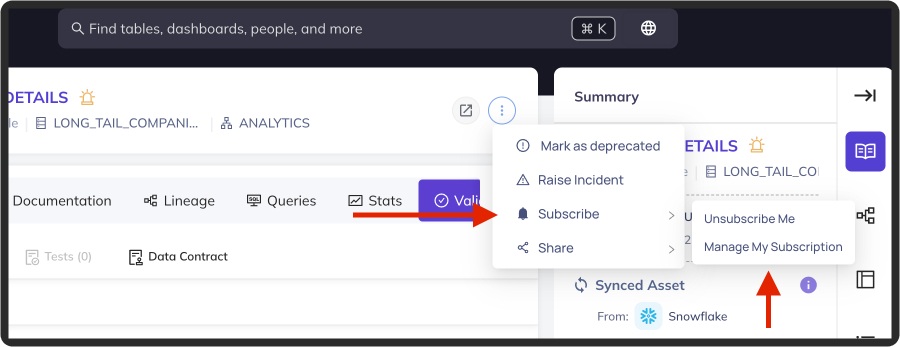 +
+ 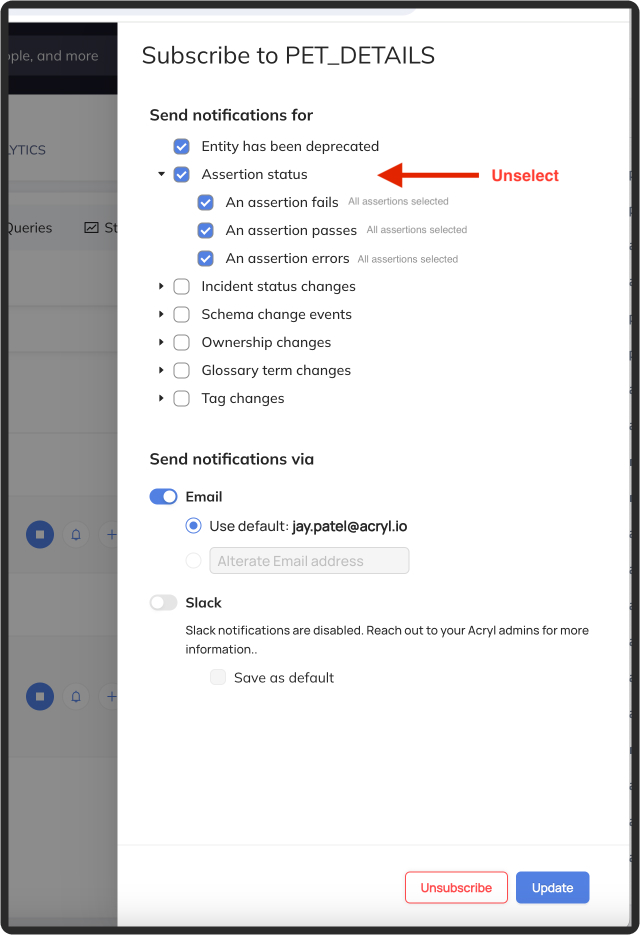 +
+
+
+
+Then select individual assertions you'd like to subscribe to:
+
+ 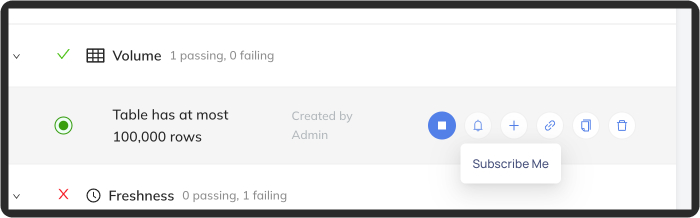 +
+
+
+
+
## FAQ
diff --git a/metadata-ingestion/developing.md b/metadata-ingestion/developing.md
index c0d004e961059..e0dbc7c8d4b14 100644
--- a/metadata-ingestion/developing.md
+++ b/metadata-ingestion/developing.md
@@ -34,7 +34,30 @@ cd metadata-ingestion-modules/airflow-plugin
../../gradlew :metadata-ingestion-modules:airflow-plugin:installDev
source venv/bin/activate
datahub version # should print "DataHub CLI version: unavailable (installed in develop mode)"
+
+# start the airflow web server
+export AIRFLOW_HOME=~/airflow
+airflow webserver --port 8090 -d
+
+# start the airflow scheduler
+airflow scheduler
+
+# access the airflow service and run any of the DAG
+# open http://localhost:8090/
+# select any DAG and click on the `play arrow` button to start the DAG
+
+# add the debug lines in the codebase, i.e. in ./src/datahub_airflow_plugin/datahub_listener.py
+logger.debug("this is the sample debug line")
+
+# run the DAG again and you can see the debug lines in the task_run log at,
+#1. click on the `timestamp` in the `Last Run` column
+#2. select the task
+#3. click on the `log` option
```
+
+
+> **P.S. if you are not able to see the log lines, then restart the `airflow scheduler` and rerun the DAG**
+
### (Optional) Set up your Python environment for developing on Dagster Plugin
From the repository root:
diff --git a/metadata-ingestion/src/datahub/entrypoints.py b/metadata-ingestion/src/datahub/entrypoints.py
index 49042db7b9299..72e9a5b045517 100644
--- a/metadata-ingestion/src/datahub/entrypoints.py
+++ b/metadata-ingestion/src/datahub/entrypoints.py
@@ -66,7 +66,7 @@
"--log-file",
type=click.Path(dir_okay=False),
default=None,
- help="Enable debug logging.",
+ help="Write debug-level logs to a file.",
)
@click.version_option(
version=datahub_package.nice_version_name(),
diff --git a/metadata-ingestion/src/datahub/ingestion/glossary/classification_mixin.py b/metadata-ingestion/src/datahub/ingestion/glossary/classification_mixin.py
index d4b649a637ffb..3e5eb4347b474 100644
--- a/metadata-ingestion/src/datahub/ingestion/glossary/classification_mixin.py
+++ b/metadata-ingestion/src/datahub/ingestion/glossary/classification_mixin.py
@@ -300,6 +300,8 @@ def classification_workunit_processor(
table_name = ".".join(table_id)
if not classification_handler.is_classification_enabled_for_table(table_name):
yield from table_wu_generator
+ return
+
for wu in table_wu_generator:
maybe_schema_metadata = wu.get_aspect_of_type(SchemaMetadata)
if (
diff --git a/metadata-ingestion/src/datahub/ingestion/source/ge_data_profiler.py b/metadata-ingestion/src/datahub/ingestion/source/ge_data_profiler.py
index b16287dcfccb4..3173dfa302399 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/ge_data_profiler.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/ge_data_profiler.py
@@ -1180,6 +1180,7 @@ def _generate_single_profile(
if custom_sql is not None:
ge_config["query"] = custom_sql
+ batch = None
with self._ge_context() as ge_context, PerfTimer() as timer:
try:
logger.info(f"Profiling {pretty_name}")
@@ -1219,7 +1220,7 @@ def _generate_single_profile(
self.report.report_warning(pretty_name, f"Profiling exception {e}")
return None
finally:
- if self.base_engine.engine.name == TRINO:
+ if batch is not None and self.base_engine.engine.name == TRINO:
self._drop_trino_temp_table(batch)
def _get_ge_dataset(
diff --git a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
index fc2733c211580..9bb6226b4947a 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/snowflake/snowflake_v2.py
@@ -257,6 +257,7 @@ def __init__(self, ctx: PipelineContext, config: SnowflakeV2Config):
graph=self.ctx.graph,
generate_usage_statistics=False,
generate_operations=False,
+ format_queries=self.config.format_sql_queries,
)
self.report.sql_aggregator = self.aggregator.report
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
index 530764e8320cd..774f0dfce3b87 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sql_parsing_aggregator.py
@@ -160,6 +160,8 @@ class SqlAggregatorReport(Report):
# SQL parsing (over all invocations).
num_sql_parsed: int = 0
sql_parsing_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
+ sql_fingerprinting_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
+ sql_formatting_timer: PerfTimer = dataclasses.field(default_factory=PerfTimer)
# Other lineage loading metrics.
num_known_query_lineage: int = 0
@@ -381,7 +383,8 @@ def _initialize_schema_resolver_from_graph(self, graph: DataHubGraph) -> None:
def _maybe_format_query(self, query: str) -> str:
if self.format_queries:
- return try_format_query(query, self.platform.platform_name)
+ with self.report.sql_formatting_timer:
+ return try_format_query(query, self.platform.platform_name)
return query
def add_known_query_lineage(
@@ -405,9 +408,12 @@ def add_known_query_lineage(
self.report.num_known_query_lineage += 1
# Generate a fingerprint for the query.
- query_fingerprint = get_query_fingerprint(
- known_query_lineage.query_text, platform=self.platform.platform_name
- )
+ with self.report.sql_fingerprinting_timer:
+ query_fingerprint = get_query_fingerprint(
+ known_query_lineage.query_text,
+ platform=self.platform.platform_name,
+ fast=True,
+ )
formatted_query = self._maybe_format_query(known_query_lineage.query_text)
# Register the query.
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py
index ddab26b28ec4f..b494dde4013a4 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py
@@ -1,6 +1,7 @@
import functools
import hashlib
import logging
+import re
from typing import Dict, Iterable, Optional, Tuple, Union
import sqlglot
@@ -109,6 +110,80 @@ def _expression_to_string(
return expression.sql(dialect=get_dialect(platform))
+_BASIC_NORMALIZATION_RULES = {
+ # Remove /* */ comments.
+ re.compile(r"/\*.*?\*/", re.DOTALL): "",
+ # Remove -- comments.
+ re.compile(r"--.*$"): "",
+ # Replace all runs of whitespace with a single space.
+ re.compile(r"\s+"): " ",
+ # Remove leading and trailing whitespace and trailing semicolons.
+ re.compile(r"^\s+|[\s;]+$"): "",
+ # Replace anything that looks like a number with a placeholder.
+ re.compile(r"\b\d+\b"): "?",
+ # Replace anything that looks like a string with a placeholder.
+ re.compile(r"'[^']*'"): "?",
+ # Replace sequences of IN/VALUES with a single placeholder.
+ re.compile(r"\b(IN|VALUES)\s*\(\?(?:, \?)*\)", re.IGNORECASE): r"\1 (?)",
+ # Normalize parenthesis spacing.
+ re.compile(r"\( "): "(",
+ re.compile(r" \)"): ")",
+}
+_TABLE_NAME_NORMALIZATION_RULES = {
+ # Replace UUID-like strings with a placeholder (both - and _ variants).
+ re.compile(
+ r"[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}",
+ re.IGNORECASE,
+ ): "00000000-0000-0000-0000-000000000000",
+ re.compile(
+ r"[0-9a-f]{8}_[0-9a-f]{4}_[0-9a-f]{4}_[0-9a-f]{4}_[0-9a-f]{12}",
+ re.IGNORECASE,
+ ): "00000000_0000_0000_0000_000000000000",
+ # GE temporary table names (prefix + 8 digits of a UUIDv4)
+ re.compile(
+ r"\b(ge_tmp_|ge_temp_|gx_temp_)[0-9a-f]{8}\b", re.IGNORECASE
+ ): r"\1abcdefgh",
+ # Date-suffixed table names (e.g. _20210101)
+ re.compile(r"\b(\w+)(19|20)\d{4}\b"): r"\1YYYYMM",
+ re.compile(r"\b(\w+)(19|20)\d{6}\b"): r"\1YYYYMMDD",
+ re.compile(r"\b(\w+)(19|20)\d{8}\b"): r"\1YYYYMMDDHH",
+ re.compile(r"\b(\w+)(19|20)\d{10}\b"): r"\1YYYYMMDDHHMM",
+}
+
+
+def generalize_query_fast(
+ expression: sqlglot.exp.ExpOrStr,
+ dialect: DialectOrStr,
+ change_table_names: bool = False,
+) -> str:
+ """Variant of `generalize_query` that only does basic normalization.
+
+ Args:
+ expression: The SQL query to generalize.
+ dialect: The SQL dialect to use.
+ change_table_names: If True, replace table names with placeholders. Note
+ that this should only be used for query filtering purposes, as it
+ violates the general assumption that the queries with the same fingerprint
+ have the same lineage/usage/etc.
+
+ Returns:
+ The generalized SQL query.
+ """
+
+ if isinstance(expression, sqlglot.exp.Expression):
+ expression = expression.sql(dialect=get_dialect(dialect))
+ query_text = expression
+
+ REGEX_REPLACEMENTS = {
+ **_BASIC_NORMALIZATION_RULES,
+ **(_TABLE_NAME_NORMALIZATION_RULES if change_table_names else {}),
+ }
+
+ for pattern, replacement in REGEX_REPLACEMENTS.items():
+ query_text = pattern.sub(replacement, query_text)
+ return query_text
+
+
def generalize_query(expression: sqlglot.exp.ExpOrStr, dialect: DialectOrStr) -> str:
"""
Generalize/normalize a SQL query.
@@ -172,11 +247,14 @@ def generate_hash(text: str) -> str:
def get_query_fingerprint_debug(
- expression: sqlglot.exp.ExpOrStr, platform: DialectOrStr
+ expression: sqlglot.exp.ExpOrStr, platform: DialectOrStr, fast: bool = False
) -> Tuple[str, Optional[str]]:
try:
- dialect = get_dialect(platform)
- expression_sql = generalize_query(expression, dialect=dialect)
+ if not fast:
+ dialect = get_dialect(platform)
+ expression_sql = generalize_query(expression, dialect=dialect)
+ else:
+ expression_sql = generalize_query_fast(expression, dialect=platform)
except (ValueError, sqlglot.errors.SqlglotError) as e:
if not isinstance(expression, str):
raise
@@ -193,7 +271,7 @@ def get_query_fingerprint_debug(
def get_query_fingerprint(
- expression: sqlglot.exp.ExpOrStr, platform: DialectOrStr
+ expression: sqlglot.exp.ExpOrStr, platform: DialectOrStr, fast: bool = False
) -> str:
"""Get a fingerprint for a SQL query.
@@ -215,7 +293,7 @@ def get_query_fingerprint(
The fingerprint for the SQL query.
"""
- return get_query_fingerprint_debug(expression, platform)[0]
+ return get_query_fingerprint_debug(expression, platform, fast=fast)[0]
@functools.lru_cache(maxsize=FORMAT_QUERY_CACHE_SIZE)
diff --git a/metadata-ingestion/tests/integration/snowflake/test_snowflake.py b/metadata-ingestion/tests/integration/snowflake/test_snowflake.py
index 81487d38eda7d..e9f6190c464f9 100644
--- a/metadata-ingestion/tests/integration/snowflake/test_snowflake.py
+++ b/metadata-ingestion/tests/integration/snowflake/test_snowflake.py
@@ -119,6 +119,7 @@ def test_snowflake_basic(pytestconfig, tmp_path, mock_time, mock_datahub_graph):
include_table_lineage=True,
include_view_lineage=True,
include_usage_stats=True,
+ format_sql_queries=True,
validate_upstreams_against_patterns=False,
include_operational_stats=True,
email_as_user_identifier=True,
@@ -213,6 +214,7 @@ def test_snowflake_private_link(pytestconfig, tmp_path, mock_time, mock_datahub_
include_views=True,
include_view_lineage=True,
include_usage_stats=False,
+ format_sql_queries=True,
incremental_lineage=False,
include_operational_stats=False,
platform_instance="instance1",
diff --git a/metadata-ingestion/tests/unit/sql_parsing/aggregator_goldens/test_add_known_query_lineage.json b/metadata-ingestion/tests/unit/sql_parsing/aggregator_goldens/test_add_known_query_lineage.json
index bfc8a1fd16dbc..3893b649bd5c8 100644
--- a/metadata-ingestion/tests/unit/sql_parsing/aggregator_goldens/test_add_known_query_lineage.json
+++ b/metadata-ingestion/tests/unit/sql_parsing/aggregator_goldens/test_add_known_query_lineage.json
@@ -18,7 +18,7 @@
},
"dataset": "urn:li:dataset:(urn:li:dataPlatform:redshift,dev.public.bar,PROD)",
"type": "TRANSFORMED",
- "query": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae"
+ "query": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f"
}
],
"fineGrainedLineages": [
@@ -32,7 +32,7 @@
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:redshift,dev.public.foo,PROD),a)"
],
"confidenceScore": 1.0,
- "query": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae"
+ "query": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f"
},
{
"upstreamType": "FIELD_SET",
@@ -44,7 +44,7 @@
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:redshift,dev.public.foo,PROD),b)"
],
"confidenceScore": 1.0,
- "query": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae"
+ "query": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f"
},
{
"upstreamType": "FIELD_SET",
@@ -56,7 +56,7 @@
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:redshift,dev.public.foo,PROD),c)"
],
"confidenceScore": 1.0,
- "query": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae"
+ "query": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f"
}
]
}
@@ -64,7 +64,7 @@
},
{
"entityType": "query",
- "entityUrn": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae",
+ "entityUrn": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f",
"changeType": "UPSERT",
"aspectName": "queryProperties",
"aspect": {
@@ -85,9 +85,29 @@
}
}
},
+{
+ "entityType": "dataset",
+ "entityUrn": "urn:li:dataset:(urn:li:dataPlatform:redshift,dev.public.foo,PROD)",
+ "changeType": "UPSERT",
+ "aspectName": "operation",
+ "aspect": {
+ "json": {
+ "timestampMillis": 1707182625000,
+ "partitionSpec": {
+ "type": "FULL_TABLE",
+ "partition": "FULL_TABLE_SNAPSHOT"
+ },
+ "operationType": "INSERT",
+ "customProperties": {
+ "query_urn": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f"
+ },
+ "lastUpdatedTimestamp": 20000
+ }
+ }
+},
{
"entityType": "query",
- "entityUrn": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae",
+ "entityUrn": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f",
"changeType": "UPSERT",
"aspectName": "querySubjects",
"aspect": {
@@ -105,7 +125,7 @@
},
{
"entityType": "query",
- "entityUrn": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae",
+ "entityUrn": "urn:li:query:6ed1d12fbf2ccc8138ceec08cc35b981030d6d004bfad9743c7afd84260fa63f",
"changeType": "UPSERT",
"aspectName": "dataPlatformInstance",
"aspect": {
@@ -113,25 +133,5 @@
"platform": "urn:li:dataPlatform:redshift"
}
}
-},
-{
- "entityType": "dataset",
- "entityUrn": "urn:li:dataset:(urn:li:dataPlatform:redshift,dev.public.foo,PROD)",
- "changeType": "UPSERT",
- "aspectName": "operation",
- "aspect": {
- "json": {
- "timestampMillis": 1707182625000,
- "partitionSpec": {
- "type": "FULL_TABLE",
- "partition": "FULL_TABLE_SNAPSHOT"
- },
- "operationType": "INSERT",
- "customProperties": {
- "query_urn": "urn:li:query:02e2ec36678bea2a8c4c855fed5255d087cfeb2710d326e95fd9b48a9c4fc0ae"
- },
- "lastUpdatedTimestamp": 20000
- }
- }
}
]
\ No newline at end of file
diff --git a/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_utils.py b/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_utils.py
index 61b5a4dc2ffb1..744d43373a0a1 100644
--- a/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_utils.py
+++ b/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_utils.py
@@ -1,5 +1,7 @@
import textwrap
+from enum import Enum
+import pytest
import sqlglot
from datahub.sql_parsing.sql_parsing_common import QueryType
@@ -9,6 +11,7 @@
)
from datahub.sql_parsing.sqlglot_utils import (
generalize_query,
+ generalize_query_fast,
get_dialect,
get_query_fingerprint,
is_dialect_instance,
@@ -49,49 +52,67 @@ def test_query_types():
) == (QueryType.CREATE_VIEW, {"kind": "VIEW"})
-def test_query_generalization():
- # Basic keyword normalization.
- assert (
- generalize_query("select * from foo", dialect="redshift") == "SELECT * FROM foo"
- )
+class QueryGeneralizationTestMode(Enum):
+ FULL = "full"
+ FAST = "fast"
+ BOTH = "both"
- # Comment removal and whitespace normalization.
- assert (
- generalize_query(
- "/* query system = foo, id = asdf */\nselect /* inline comment */ *\nfrom foo",
- dialect="redshift",
- )
- == "SELECT * FROM foo"
- )
- # Parameter normalization.
- assert (
- generalize_query(
+@pytest.mark.parametrize(
+ "query, dialect, expected, mode",
+ [
+ # Basic keyword normalization.
+ (
+ "select * from foo",
+ "redshift",
+ "SELECT * FROM foo",
+ QueryGeneralizationTestMode.FULL,
+ ),
+ # Comment removal and whitespace normalization.
+ (
+ "/* query system = foo, id = asdf */\nSELECT /* inline comment */ *\nFROM foo",
+ "redshift",
+ "SELECT * FROM foo",
+ QueryGeneralizationTestMode.BOTH,
+ ),
+ # Parameter normalization.
+ (
"UPDATE \"books\" SET page_count = page_count + 1, author_count = author_count + 1 WHERE book_title = 'My New Book'",
- dialect="redshift",
- )
- == 'UPDATE "books" SET page_count = page_count + ?, author_count = author_count + ? WHERE book_title = ?'
- )
- assert (
- generalize_query(
- "select * from foo where date = '2021-01-01'", dialect="redshift"
- )
- == "SELECT * FROM foo WHERE date = ?"
- )
- assert (
- generalize_query(
- "select * from books where category in ('fiction', 'biography', 'fantasy')",
- dialect="redshift",
- )
- == "SELECT * FROM books WHERE category IN (?)"
- )
- assert (
- generalize_query(
+ "redshift",
+ 'UPDATE "books" SET page_count = page_count + ?, author_count = author_count + ? WHERE book_title = ?',
+ QueryGeneralizationTestMode.BOTH,
+ ),
+ (
+ "SELECT * FROM foo WHERE date = '2021-01-01'",
+ "redshift",
+ "SELECT * FROM foo WHERE date = ?",
+ QueryGeneralizationTestMode.BOTH,
+ ),
+ (
+ "SELECT * FROM books WHERE category IN ('fiction', 'biography', 'fantasy')",
+ "redshift",
+ "SELECT * FROM books WHERE category IN (?)",
+ QueryGeneralizationTestMode.BOTH,
+ ),
+ (
+ textwrap.dedent(
+ """\
+ INSERT INTO MyTable
+ (Column1, Column2, Column3)
+ VALUES
+ ('John', 123, 'Lloyds Office');
+ """
+ ),
+ "mssql",
+ "INSERT INTO MyTable (Column1, Column2, Column3) VALUES (?)",
+ QueryGeneralizationTestMode.BOTH,
+ ),
+ (
textwrap.dedent(
"""\
/* Copied from https://stackoverflow.com/a/452934/5004662 */
INSERT INTO MyTable
- ( Column1, Column2, Column3 )
+ (Column1, Column2, Column3)
VALUES
/* multiple value rows */
('John', 123, 'Lloyds Office'),
@@ -100,10 +121,42 @@ def test_query_generalization():
('Miranda', 126, 'Bristol Office');
"""
),
- dialect="mssql",
+ "mssql",
+ "INSERT INTO MyTable (Column1, Column2, Column3) VALUES (?), (?), (?), (?)",
+ QueryGeneralizationTestMode.FULL,
+ ),
+ # Test table name normalization.
+ # These are only supported with fast normalization.
+ (
+ "SELECT * FROM datahub_community.fivetran_interval_unconstitutional_staging.datahub_slack_mess-staging-480fd5a7-58f4-4cc9-b6fb-87358788efe6",
+ "bigquery",
+ "SELECT * FROM datahub_community.fivetran_interval_unconstitutional_staging.datahub_slack_mess-staging-00000000-0000-0000-0000-000000000000",
+ QueryGeneralizationTestMode.FAST,
+ ),
+ (
+ "SELECT * FROM datahub_community.maggie.commonroom_slack_members_20240315",
+ "bigquery",
+ "SELECT * FROM datahub_community.maggie.commonroom_slack_members_YYYYMMDD",
+ QueryGeneralizationTestMode.FAST,
+ ),
+ (
+ "SELECT COUNT(*) FROM ge_temp_aa91f1fd",
+ "bigquery",
+ "SELECT COUNT(*) FROM ge_temp_abcdefgh",
+ QueryGeneralizationTestMode.FAST,
+ ),
+ ],
+)
+def test_query_generalization(
+ query: str, dialect: str, expected: str, mode: QueryGeneralizationTestMode
+) -> None:
+ if mode in {QueryGeneralizationTestMode.FULL, QueryGeneralizationTestMode.BOTH}:
+ assert generalize_query(query, dialect=dialect) == expected
+ if mode in {QueryGeneralizationTestMode.FAST, QueryGeneralizationTestMode.BOTH}:
+ assert (
+ generalize_query_fast(query, dialect=dialect, change_table_names=True)
+ == expected
)
- == "INSERT INTO MyTable (Column1, Column2, Column3) VALUES (?), (?), (?), (?)"
- )
def test_query_fingerprint():