By Reon Ho, Lam Cheng Jun, Janson Chew, and Bryan Koh
- Problem Description (Brief Write Up)
- Exploratory Data Analysis (EDA)
- Data Pre-processing
- Model Selection
- Evaluation
- Discussion and Possible Improvements
The goal of this project is to predict a binary target feature (default or not) valued 0 (= not default) or 1 (= default). This project will cover the entire data science pipeline, from data analysis to model evaluation. We will be trying several models to predict default status, and choosing the most appropriate one at the end.
The data set we will be working on contains payment information of 30,000 credit card holders obtained from a bank in Taiwan, and each data sample is described by 23 feature attributes and the binary target feature (default or not).
The 23 explanatory attributes and their explanations (from the data provider) are as follows:
X1: Amount of the given credit (NT dollar): it includes both the individual consumer credit and his/her family (supplementary) credit.
X2: Gender (1 = male; 2 = female).
X3: Education (1 = graduate school; 2 = university; 3 = high school; 4 = others).
X4: Marital status (1 = married; 2 = single; 3 = others).
X5: Age (year).
The measurement scale for the repayment status is: -1 = pay duly; 1 = payment delay for one month; 2 = payment delay for two months, . . . 8 = payment delay for eight months; 9 = payment delay for nine months and above.
X6 = the repayment status in September, 2005
X7 = the repayment status in August, 2005
X8 = the repayment status in July, 2005
X9 = the repayment status in June, 2005
X10 = the repayment status in May, 2005
X11 = the repayment status in April, 2005.
X12 = amount of bill statement in September, 2005;
X13 = amount of bill statement in August, 2005
. . .
X17 = amount of bill statement in April, 2005.
X18 = amount paid in September, 2005
X19 = amount paid in August, 2005
. . .
X23 = amount paid in April, 2005.
In this section we will explore the data set, its shape and its features to get an idea of the data.
import pandas as pdimport matplotlib.pyplot as plt
import seaborn as snsimport numpy as npurl = 'https://raw.githubusercontent.com/reonho/bt2101disrudy/master/card.csv'
df = pd.read_csv(url, header = 1, index_col = 0)
# Dataset is now stored in a Pandas Dataframe#rename the target variable to "Y" for convenience
df["Y"] = df["default payment next month"]
df = df.drop("default payment next month", axis = 1)
df0 = df #backup of df
df.head().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | Y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | |||||||||||||||||||||
| 1 | 20000 | 2 | 2 | 1 | 24 | 2 | 2 | -1 | -1 | -2 | ... | 0 | 0 | 0 | 0 | 689 | 0 | 0 | 0 | 0 | 1 |
| 2 | 120000 | 2 | 2 | 2 | 26 | -1 | 2 | 0 | 0 | 0 | ... | 3272 | 3455 | 3261 | 0 | 1000 | 1000 | 1000 | 0 | 2000 | 1 |
| 3 | 90000 | 2 | 2 | 2 | 34 | 0 | 0 | 0 | 0 | 0 | ... | 14331 | 14948 | 15549 | 1518 | 1500 | 1000 | 1000 | 1000 | 5000 | 0 |
| 4 | 50000 | 2 | 2 | 1 | 37 | 0 | 0 | 0 | 0 | 0 | ... | 28314 | 28959 | 29547 | 2000 | 2019 | 1200 | 1100 | 1069 | 1000 | 0 |
| 5 | 50000 | 1 | 2 | 1 | 57 | -1 | 0 | -1 | 0 | 0 | ... | 20940 | 19146 | 19131 | 2000 | 36681 | 10000 | 9000 | 689 | 679 | 0 |
5 rows × 24 columns
size = df.shape
print("Data has {} Columns and {} Rows".format(size[1], size[0]))Data has 24 Columns and 30000 Rows
#check for null values
df.isnull().any().sum() 0
From the above analyses, we observe that:
- The data indeed has 30000 rows and 24 columns
- There are no null values
We will now explore the features more in depth.
1) Exploring target attribute:
All = df.shape[0]
default = df[df['Y'] == 1]
nondefault = df[df['Y'] == 0]
x = len(default)/All
y = len(nondefault)/All
print('defaults :',x*100,'%')
print('non defaults :',y*100,'%')
# plotting target attribute against frequency
labels = ['non default','default']
classes = pd.value_counts(df['Y'], sort = True)
classes.plot(kind = 'bar', rot=0)
plt.title("Target attribute distribution")
plt.xticks(range(2), labels)
plt.xlabel("Class")
plt.ylabel("Frequency")defaults : 22.12 %
non defaults : 77.88000000000001 %
Text(0, 0.5, 'Frequency')

2) Exploring categorical attributes
Categorical attributes are:
- Sex
- Education
- Marriage
print(df["SEX"].value_counts().apply(lambda r: r/All*100))
print("--------------------------------------------------------")
print(df["EDUCATION"].value_counts().apply(lambda r: r/All*100))
print("--------------------------------------------------------")
print(df["MARRIAGE"].value_counts().apply(lambda r: r/All*100))2 60.373333
1 39.626667
Name: SEX, dtype: float64
--------------------------------------------------------
2 46.766667
1 35.283333
3 16.390000
5 0.933333
4 0.410000
6 0.170000
0 0.046667
Name: EDUCATION, dtype: float64
--------------------------------------------------------
2 53.213333
1 45.530000
3 1.076667
0 0.180000
Name: MARRIAGE, dtype: float64
Findings
- Categorical variable SEX does not seem to have any missing/extra groups, and it is separated into Male = 1 and Female = 2
- Categorical variable MARRIAGE seems to have unknown group = 0, which could be assumed to be missing data, with other groups being Married = 1, Single = 2, Others = 3
- Categorical variable EDUCATION seems to have unknown group = 0,5,6, with other groups being graduate school = 1, university = 2, high school = 3, others = 4
#proportion of target attribute (for reference)
print('Total target attributes:')
print('non defaults :',y*100,'%')
print('defaults :',x*100,'%')
print("--------------------------------------------------------")
#analysing default payment with Sex
sex_target = pd.crosstab(df["Y"], df["SEX"]).apply(lambda r: r/r.sum()*100).rename(columns = {1: "Male", 2: "Female"}, index = {0: "non defaults", 1: "defaults"})
print(sex_target)
print("--------------------------------------------------------")
#analysing default payment with education
education_target = pd.crosstab(df["Y"], df["EDUCATION"]).apply(lambda r: r/r.sum()*100).rename(index = {0: "non defaults", 1: "defaults"})
print(education_target)
print("--------------------------------------------------------")
#analysing default payment with marriage
marriage_target = pd.crosstab(df["Y"], df["MARRIAGE"]).apply(lambda r: r/r.sum()*100).rename(columns = {0: "unknown",1: "married", 2: "single", 3: "others"},index = {0: "non defaults", 1: "defaults"})
print(marriage_target)Total target attributes:
non defaults : 77.88000000000001 %
defaults : 22.12 %
--------------------------------------------------------
SEX Male Female
Y
non defaults 75.832773 79.223719
defaults 24.167227 20.776281
--------------------------------------------------------
EDUCATION 0 1 2 3 4 5 \
Y
non defaults 100.0 80.765234 76.265146 74.842384 94.308943 93.571429
defaults 0.0 19.234766 23.734854 25.157616 5.691057 6.428571
EDUCATION 6
Y
non defaults 84.313725
defaults 15.686275
--------------------------------------------------------
MARRIAGE unknown married single others
Y
non defaults 90.740741 76.528296 79.071661 73.993808
defaults 9.259259 23.471704 20.928339 26.006192
Conclusion
From the analyses above we conclude that
- The categorical data is noisy - EDUCATION and MARRIAGE contains unexplained/anomalous data.
3) Analysis of Numerical Attributes
The numerical attributes are:
#printing numerical attributes
pd.DataFrame(df.drop(['SEX', 'EDUCATION', 'MARRIAGE','Y'], axis = 1).columns).transpose().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | LIMIT_BAL | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | PAY_6 | BILL_AMT1 | BILL_AMT2 | BILL_AMT3 | BILL_AMT4 | BILL_AMT5 | BILL_AMT6 | PAY_AMT1 | PAY_AMT2 | PAY_AMT3 | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 |
df.drop(['SEX', 'EDUCATION', 'MARRIAGE','Y'], axis=1).describe().transpose().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| LIMIT_BAL | 30000.0 | 167484.322667 | 129747.661567 | 10000.0 | 50000.00 | 140000.0 | 240000.00 | 1000000.0 |
| AGE | 30000.0 | 35.485500 | 9.217904 | 21.0 | 28.00 | 34.0 | 41.00 | 79.0 |
| PAY_0 | 30000.0 | -0.016700 | 1.123802 | -2.0 | -1.00 | 0.0 | 0.00 | 8.0 |
| PAY_2 | 30000.0 | -0.133767 | 1.197186 | -2.0 | -1.00 | 0.0 | 0.00 | 8.0 |
| PAY_3 | 30000.0 | -0.166200 | 1.196868 | -2.0 | -1.00 | 0.0 | 0.00 | 8.0 |
| PAY_4 | 30000.0 | -0.220667 | 1.169139 | -2.0 | -1.00 | 0.0 | 0.00 | 8.0 |
| PAY_5 | 30000.0 | -0.266200 | 1.133187 | -2.0 | -1.00 | 0.0 | 0.00 | 8.0 |
| PAY_6 | 30000.0 | -0.291100 | 1.149988 | -2.0 | -1.00 | 0.0 | 0.00 | 8.0 |
| BILL_AMT1 | 30000.0 | 51223.330900 | 73635.860576 | -165580.0 | 3558.75 | 22381.5 | 67091.00 | 964511.0 |
| BILL_AMT2 | 30000.0 | 49179.075167 | 71173.768783 | -69777.0 | 2984.75 | 21200.0 | 64006.25 | 983931.0 |
| BILL_AMT3 | 30000.0 | 47013.154800 | 69349.387427 | -157264.0 | 2666.25 | 20088.5 | 60164.75 | 1664089.0 |
| BILL_AMT4 | 30000.0 | 43262.948967 | 64332.856134 | -170000.0 | 2326.75 | 19052.0 | 54506.00 | 891586.0 |
| BILL_AMT5 | 30000.0 | 40311.400967 | 60797.155770 | -81334.0 | 1763.00 | 18104.5 | 50190.50 | 927171.0 |
| BILL_AMT6 | 30000.0 | 38871.760400 | 59554.107537 | -339603.0 | 1256.00 | 17071.0 | 49198.25 | 961664.0 |
| PAY_AMT1 | 30000.0 | 5663.580500 | 16563.280354 | 0.0 | 1000.00 | 2100.0 | 5006.00 | 873552.0 |
| PAY_AMT2 | 30000.0 | 5921.163500 | 23040.870402 | 0.0 | 833.00 | 2009.0 | 5000.00 | 1684259.0 |
| PAY_AMT3 | 30000.0 | 5225.681500 | 17606.961470 | 0.0 | 390.00 | 1800.0 | 4505.00 | 896040.0 |
| PAY_AMT4 | 30000.0 | 4826.076867 | 15666.159744 | 0.0 | 296.00 | 1500.0 | 4013.25 | 621000.0 |
| PAY_AMT5 | 30000.0 | 4799.387633 | 15278.305679 | 0.0 | 252.50 | 1500.0 | 4031.50 | 426529.0 |
| PAY_AMT6 | 30000.0 | 5215.502567 | 17777.465775 | 0.0 | 117.75 | 1500.0 | 4000.00 | 528666.0 |
Analysis of PAY_0 to PAY_6
We observe that the minimum value of PAY_0 to PAY_6 is -2. The dataset's author has explained these factors (PAY_0 to PAY_6) as the number of months of payment delay, that is, 1= payment delay of one month; 2= payment delay of two months and so on.
However, the presence of -2, -1 in these columns indicates that
- There is anomalous data, OR
- The numbers do not strictly correspond to the number of months of payment delay.
This means we must conduct some data transformation.
According to the datasets' author, the numeric value in these attributes shows the past history of a credit card holder, where -2 means: No consumption of credit card, -1 means that holder paid the full balance, and 0 means the use of revolving credit.
def draw_histograms(df, variables, n_rows, n_cols, n_bins):
fig=plt.figure()
for i, var_name in enumerate(variables):
ax=fig.add_subplot(n_rows,n_cols,i+1)
df[var_name].hist(bins=n_bins,ax=ax)
ax.set_title(var_name)
fig.tight_layout() # Improves appearance a bit.
plt.show()
PAY = df[['PAY_0','PAY_2', 'PAY_3', 'PAY_4', 'PAY_5', 'PAY_6']]
BILLAMT = df[['BILL_AMT1','BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4', 'BILL_AMT5', 'BILL_AMT6']]
PAYAMT = df[['PAY_AMT1','PAY_AMT2', 'PAY_AMT3', 'PAY_AMT4', 'PAY_AMT5', 'PAY_AMT6']]
draw_histograms(PAY, PAY.columns, 2, 3, 10)
draw_histograms(BILLAMT, BILLAMT.columns, 2, 3, 10)
draw_histograms(PAYAMT, PAYAMT.columns, 2, 3, 10)


We observe that the "repayment status" attributes are the most highly correlated with the target variable and we would expect them to be more significant in predicting credit default. In fact the later the status (pay_0 is later than pay_6), the more correlated it is.
Now that we have an idea of the features, we will move on to feature selection and data preparation.
It was previously mentioned that our data had a bit of noise, so we will clean up the data in this part. Additionally, we will conduct some feature selection.
- Removing Noise - Inconsistencies
- Dealing with negative values of PAY_0 to PAY_6
- Outliers
- One Hot Encoding
- Train Test Split
- Feature selection
First, we found in our data exploration that education has unknown groups 0, 5 and 6. These will be dealt with using the identification method. 0 will be assumed to be missing data and identified. Groups 5 and 6 will be subsumed by Education = Others, with value 4
df['EDUCATION'].replace([5,6], 4, regex=True, inplace=True)
df["EDUCATION"].unique()array([2, 1, 3, 4, 0], dtype=int64)
Similarly, for Marriage, we will use the identification method to deal with missing data. So 0 will be treated as a new category, "Missing"
Second, we are going to extract the negative values of PAY_0 to PAY_6 as another categorical feature. This way, PAY_0 to PAY_6 can be thought of purely as the months of delay of payments.
The negative values will form a categorical variable. e.g. negative values of PAY_0 will form the categorical variable S_0.
for i in range(0,7):
try:
df["S_" + str(i)] = [x if x < 1 else 1 for x in df["PAY_" + str(i)]]
except:
passprint('Dummy variables for negative values')
df[["S_0", "S_2", "S_3", "S_4", "S_5", "S_6"]].head()Dummy variables for negative values
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| S_0 | S_2 | S_3 | S_4 | S_5 | S_6 | |
|---|---|---|---|---|---|---|
| ID | ||||||
| 1 | 1 | 1 | -1 | -1 | -2 | -2 |
| 2 | -1 | 1 | 0 | 0 | 0 | 1 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | -1 | 0 | -1 | 0 | 0 | 0 |
#attributes representing positive values
for col in ["PAY_0", "PAY_2", "PAY_3", "PAY_4", "PAY_5", "PAY_6"]:
df[col].replace([0,-1,-2], 0, regex=True, inplace=True)Next, we would like to remove outliers from the continuous variables. Assuming that all the data points are normally distributed, we will consider a point an outlier if it falls outside the 99% interval of a distribution. (Critical value = 2.58)
from scipy import stats
#we are only concerned with the ordinal data
o = pd.DataFrame(df.drop(['Y','EDUCATION', 'MARRIAGE', "SEX","S_0", "S_2", "S_3", "S_4", "S_5", "S_6","PAY_0", "PAY_2", "PAY_3", "PAY_4", "PAY_5", "PAY_6"], axis=1))
#rows where the absolute z score of all columns are less than 2.58 (critical value)
rows = (np.abs(stats.zscore(o)) < 2.58).all(axis=1)
df = df[rows]
df.describe().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | Y | S_0 | S_2 | S_3 | S_4 | S_5 | S_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | ... | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 | 26245.000000 |
| mean | 149324.899981 | 1.608954 | 1.850753 | 1.558773 | 35.006592 | 0.372109 | 0.337321 | 0.324633 | 0.278224 | 0.238750 | ... | 2787.425071 | 2778.830673 | 2822.285007 | 0.230177 | -0.133587 | -0.300438 | -0.327300 | -0.364412 | -0.395999 | -0.428158 |
| std | 116558.616530 | 0.487994 | 0.738175 | 0.522639 | 8.832028 | 0.765730 | 0.814878 | 0.811491 | 0.786314 | 0.743923 | ... | 4835.081906 | 4751.263287 | 5271.198100 | 0.420954 | 0.879876 | 0.883472 | 0.895264 | 0.886115 | 0.877789 | 0.900723 |
| min | 10000.000000 | 1.000000 | 0.000000 | 0.000000 | 21.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | -2.000000 | -2.000000 | -2.000000 | -2.000000 | -2.000000 | -2.000000 |
| 25% | 50000.000000 | 1.000000 | 1.000000 | 1.000000 | 28.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 150.000000 | 82.000000 | 0.000000 | 0.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 | -1.000000 |
| 50% | 120000.000000 | 2.000000 | 2.000000 | 2.000000 | 34.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 1200.000000 | 1218.000000 | 1143.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 75% | 210000.000000 | 2.000000 | 2.000000 | 2.000000 | 41.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 3118.000000 | 3140.000000 | 3069.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| max | 500000.000000 | 2.000000 | 4.000000 | 3.000000 | 59.000000 | 8.000000 | 8.000000 | 8.000000 | 8.000000 | 8.000000 | ... | 45171.000000 | 44197.000000 | 51000.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
8 rows × 30 columns
The models used subsequently may have difficulty converging before the maximum number of iterations allowed is reached if the data is not normalized. Additionaly, Multi-layer Perceptron is sensitive to feature scaling, so we will use StandardScaler for standardization. We only want to scale the numerical factors.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
cols = df.drop(['Y','EDUCATION', 'MARRIAGE', "SEX","S_0", "S_2", "S_3", "S_4", "S_5", "S_6","PAY_0", "PAY_2", "PAY_3", "PAY_4", "PAY_5", "PAY_6"], axis =1)
df1 = df.copy()
df1[cols.columns] = scaler.fit_transform(cols)
df = df1df1.head().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| LIMIT_BAL | SEX | EDUCATION | MARRIAGE | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | ... | PAY_AMT4 | PAY_AMT5 | PAY_AMT6 | Y | S_0 | S_2 | S_3 | S_4 | S_5 | S_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | |||||||||||||||||||||
| 1 | 0.020408 | 2 | 2 | 1 | 0.078947 | 2 | 2 | 0 | 0 | 0 | ... | 0.000000 | 0.000000 | 0.000000 | 1 | 1 | 1 | -1 | -1 | -2 | -2 |
| 2 | 0.224490 | 2 | 2 | 2 | 0.131579 | 0 | 2 | 0 | 0 | 0 | ... | 0.022138 | 0.000000 | 0.039216 | 1 | -1 | 1 | 0 | 0 | 0 | 1 |
| 3 | 0.163265 | 2 | 2 | 2 | 0.342105 | 0 | 0 | 0 | 0 | 0 | ... | 0.022138 | 0.022626 | 0.098039 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0.081633 | 2 | 2 | 1 | 0.421053 | 0 | 0 | 0 | 0 | 0 | ... | 0.024352 | 0.024187 | 0.019608 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 0.081633 | 1 | 2 | 1 | 0.947368 | 0 | 0 | 0 | 0 | 0 | ... | 0.199243 | 0.015589 | 0.013314 | 0 | -1 | 0 | -1 | 0 | 0 | 0 |
5 rows × 30 columns
In some models, categorical variables which are encoded numerically will be erroneously treated as ordinal data. To understand why this is a problem, consider the "Education" column for our dataset.
A logistic regression model, for example, will assume that the difference in odds of default between education = 1 and education = 2 is the same as the difference between education = 2 and 3. This is wrong because the difference in odds between a graduate degree and university (1 and 2) is likely to be different from that between univeristy education and high school education (2 and 3).
One hot encoding will allow our models to treat these columns explicitly as categorical features.
The following categorical columns will be one-hot encoded
- EDUCATION
- MARRIAGE
- S0 - S6
from sklearn.preprocessing import OneHotEncoderonenc = OneHotEncoder(categories='auto')#one hot encoding for EDUCATION and MARRIAGE
onehot = pd.DataFrame(onenc.fit_transform(df[['EDUCATION', 'MARRIAGE']]).toarray())
onehot.columns= names = ["MISSING-EDU","GRAD","UNI","HS","OTHER-EDU","MISSING-MS","MARRIED","SINGLE","OTHER-MS"]
#drop one of each category to prevent dummy variable trap
onehot = onehot.drop(["OTHER-EDU", "OTHER-MS"], axis = 1)
onehot.head().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| MISSING-EDU | GRAD | UNI | HS | MISSING-MS | MARRIED | SINGLE | |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 2 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 3 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 |
#one hot encoding for S_0 to S_6
onehot_PAY = pd.DataFrame(onenc.fit_transform(df[['S_0', 'S_2', 'S_3', 'S_4', 'S_5', 'S_6']]).toarray())
onehot_PAY.columns= onenc.fit(df[["S_0", "S_2", "S_3", "S_4", "S_5", "S_6"]]).get_feature_names()
#drop one of each category to prevent dummy variable trap
#onehot = onehot.drop(["OTHER-EDU", "OTHER_MS"], axis = 1)
names = []
for X in range(0,7):
if X == 1:
continue
names.append("PAY_"+str(X)+"_No_Transactions")
names.append("PAY_"+str(X)+"_Pay_Duly")
names.append("PAY_"+str(X)+"_Revolving_Credit")
try:
onehot_PAY = onehot_PAY.drop("x" + str(X) +"_1", axis =1)
except:
onehot_PAY = onehot_PAY.drop("x1_1", axis =1)
onehot_PAY.columns = names
onehot_PAY.head().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| PAY_0_No_Transactions | PAY_0_Pay_Duly | PAY_0_Revolving_Credit | PAY_2_No_Transactions | PAY_2_Pay_Duly | PAY_2_Revolving_Credit | PAY_3_No_Transactions | PAY_3_Pay_Duly | PAY_3_Revolving_Credit | PAY_4_No_Transactions | PAY_4_Pay_Duly | PAY_4_Revolving_Credit | PAY_5_No_Transactions | PAY_5_Pay_Duly | PAY_5_Revolving_Credit | PAY_6_No_Transactions | PAY_6_Pay_Duly | PAY_6_Revolving_Credit | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 1 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 3 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
| 4 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 |
df1 = df.drop(['EDUCATION', 'MARRIAGE','S_0', 'S_2', 'S_3', 'S_4', 'S_5', 'S_6'], axis = 1)
df1 = pd.concat([df1.reset_index(drop=True), onehot], axis=1)
df1 = pd.concat([df1.reset_index(drop=True), onehot_PAY], axis=1)
df1.columnsIndex(['LIMIT_BAL', 'SEX', 'AGE', 'PAY_0', 'PAY_2', 'PAY_3', 'PAY_4', 'PAY_5',
'PAY_6', 'BILL_AMT1', 'BILL_AMT2', 'BILL_AMT3', 'BILL_AMT4',
'BILL_AMT5', 'BILL_AMT6', 'PAY_AMT1', 'PAY_AMT2', 'PAY_AMT3',
'PAY_AMT4', 'PAY_AMT5', 'PAY_AMT6', 'Y', 'MISSING-EDU', 'GRAD', 'UNI',
'HS', 'MISSING-MS', 'MARRIED', 'SINGLE', 'PAY_0_No_Transactions',
'PAY_0_Pay_Duly', 'PAY_0_Revolving_Credit', 'PAY_2_No_Transactions',
'PAY_2_Pay_Duly', 'PAY_2_Revolving_Credit', 'PAY_3_No_Transactions',
'PAY_3_Pay_Duly', 'PAY_3_Revolving_Credit', 'PAY_4_No_Transactions',
'PAY_4_Pay_Duly', 'PAY_4_Revolving_Credit', 'PAY_5_No_Transactions',
'PAY_5_Pay_Duly', 'PAY_5_Revolving_Credit', 'PAY_6_No_Transactions',
'PAY_6_Pay_Duly', 'PAY_6_Revolving_Credit'],
dtype='object')
#check for perfect collinearity
corr = df1.corr()
for i in range(len(corr)):
corr.iloc[i,i] = 0
#corr[corr == 1] = 0
corr[corr.eq(1).any(1)].dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| LIMIT_BAL | SEX | AGE | PAY_0 | PAY_2 | PAY_3 | PAY_4 | PAY_5 | PAY_6 | BILL_AMT1 | ... | PAY_3_Revolving_Credit | PAY_4_No_Transactions | PAY_4_Pay_Duly | PAY_4_Revolving_Credit | PAY_5_No_Transactions | PAY_5_Pay_Duly | PAY_5_Revolving_Credit | PAY_6_No_Transactions | PAY_6_Pay_Duly | PAY_6_Revolving_Credit |
|---|
0 rows × 47 columns
size = df1.shape
print("Data has {} Columns and {} Rows".format(size[1], size[0]))Data has 47 Columns and 26245 Rows
Before we conduct feature selection and model selection, we split the data using a train test split according to the project description.
from sklearn.metrics import *
from sklearn.model_selection import *#using holdout sampling for train test split using seed 123
np.random.seed(123)
ft = df1.drop("Y", axis = 1)
target = df1["Y"]
X_train,X_test,y_train,y_test = train_test_split(ft,target,test_size=1/3)The filter method for feature selection entails selecting relevant attributes before moving on to learning phase. We will utitlise univariate feature selection to reduce the features to the fewer more significant attributes.
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
selector = SelectKBest( score_func = chi2, k=10)
selector.fit(X_train, y_train)
np.set_printoptions(precision=10)
chi2data = pd.DataFrame(selector.scores_)
chi2data["pval"] = 1 - stats.chi2.cdf(chi2data, 43)
chi2data.index = X_train.columns
print("Significant values are:")
print(chi2data[chi2data["pval"] < 0.05])
cols = chi2data[chi2data["pval"] < 0.05].index
X_train_filter = X_train[cols]
X_test_filter = X_test[cols]Significant values are:
0 pval
LIMIT_BAL 82.306062 2.883753e-04
PAY_0 4279.993739 0.000000e+00
PAY_2 3557.072141 0.000000e+00
PAY_3 2766.119390 0.000000e+00
PAY_4 2736.965012 0.000000e+00
PAY_5 2587.002458 0.000000e+00
PAY_6 2240.874786 0.000000e+00
PAY_0_No_Transactions 76.858872 1.147939e-03
PAY_0_Revolving_Credit 480.805794 0.000000e+00
PAY_2_Pay_Duly 75.283344 1.684018e-03
PAY_2_Revolving_Credit 229.527990 0.000000e+00
PAY_3_Pay_Duly 86.995856 8.229607e-05
PAY_3_Revolving_Credit 121.059740 2.357071e-09
PAY_4_Pay_Duly 79.449207 6.014800e-04
PAY_4_Revolving_Credit 82.276504 2.906105e-04
PAY_5_Pay_Duly 63.330298 2.338310e-02
PAY_5_Revolving_Credit 64.659773 1.792035e-02
In this part, we will fit machine learning models learnt in BT2101 to this classification problem, and pick the model that can produce the best results.
We will be attempting to fit the following models:
- Decision Tree
- Logistic Regression
- Support Vector Machine
- Neural Network
To make things easier, we define a get_roc function that will plot an ROC curve for all the models we evaluate, and a confusion matrix function.
def get_roc(model, y_test, X_test, name):
try:
fpr = roc_curve(y_test,model.predict_proba(X_test)[:,1])[0]
tpr = roc_curve(y_test,model.predict_proba(X_test)[:,1])[1]
thresholds = roc_curve(y_test,model.predict_proba(X_test)[:,1])[2]
except:
fpr = roc_curve(y_test,model.predict(X_test))[0]
tpr = roc_curve(y_test,model.predict(X_test))[1]
thresholds = roc_curve(y_test,model.predict(X_test))[2]
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic for ' + name)
plt.plot(fpr,tpr,label='ROC curve (AUC = %0.2f)' % (auc(fpr, tpr)))
plt.legend(loc="lower right")
#find- best threshold
optimal_idx = np.argmax(tpr - fpr)
optimal_threshold = thresholds[optimal_idx]
print("Optimal Threshold: " + str(optimal_threshold))
plt.show()
return auc(fpr, tpr)def get_optimal(model, y_test, X_test, name):
try:
fpr = roc_curve(y_test,model.predict_proba(X_test)[:,1])[0]
tpr = roc_curve(y_test,model.predict_proba(X_test)[:,1])[1]
thresholds = roc_curve(y_test,model.predict_proba(X_test)[:,1])[2]
except:
fpr = roc_curve(y_test,model.predict(X_test))[0]
tpr = roc_curve(y_test,model.predict(X_test))[1]
thresholds = roc_curve(y_test,model.predict(X_test))[2]
optimal_idx = np.argmax(tpr - fpr)
optimal_threshold = thresholds[optimal_idx]
return optimal_threshold def confusion(y_test, predictions, name):
conf = pd.crosstab(y_test,predictions, rownames=['Actual'], colnames=['Predicted'])
print("Of " + str(conf[0][1] + conf[1][1]) + " Defaulters, the " + name + " identified " + str(conf[1][1]))
return confWe will select the model based on the model evaluation. The key metrics we will compute are:
- Accuracy
- Recall
- AUROC
Because of the nature of a default detection problem, we would like to prioritise recall for defaults. This means we will place more importance in correctly identifying a defaulter than avoiding misclassifying a non-defaulter. (Assumming that the bank loses more money when lending to a defaulter than not lending to a non-defaulter)
However, simply predicting every data point as a defaulter will give us 100% recall. We have to also consider accuracy and AUROC to get a better idea of how our model performs.
evaluation = pd.DataFrame(columns=['Model', 'F1-1', 'AUROC'])The decision tree algorithm aims to recursively split the data points in the training set until the data points are completely separated or well separated. At each iteration, the tree splits the datasets by the feature(s) that give the maximum reduction in heterogeneity, which is calculated by a heterogeneity index.
Below is a binary decision tree that has been split for a few iterations.
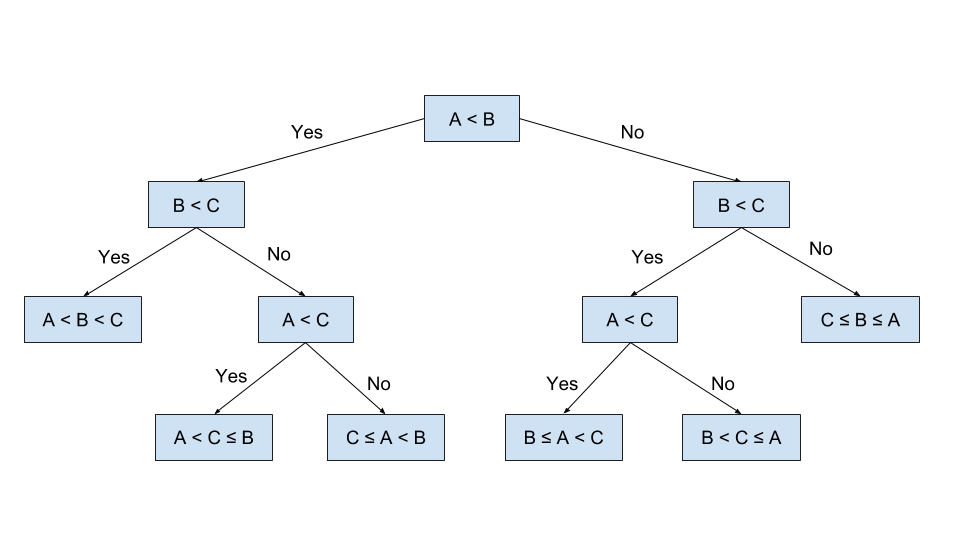
Since the target for this project is binary (fraud = yes or no) we will be building a binary decision tree, using the the GINI Index as the Heterogeneity index. The GINI is given by:
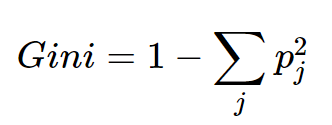
The GINI index measures how heterogenous a single node is (0 being completely homogenous and 1 being heterogenous). For each possible split, we will calculate the weighted sum of the GINI indices of the child nodes, and choose the split that results in the maximum information gain. i.e. reduction in the weighted sum of the GINI Index.
We will now construct a simple decision tree using the GINI index.
from sklearn.tree import DecisionTreeClassifiertree = DecisionTreeClassifier()
tree.fit(X_train, y_train)DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
get_roc(tree, y_train, X_train, "Decision Tree (GINI)")
print(classification_report(y_train, tree.predict(X_train)))Optimal Threshold: 0.3333333333333333

precision recall f1-score support
0 1.00 1.00 1.00 13442
1 1.00 1.00 1.00 4054
accuracy 1.00 17496
macro avg 1.00 1.00 1.00 17496
weighted avg 1.00 1.00 1.00 17496
The training set accuracy is 1, which means the datapoints are completely separated by the decision tree. We evaluate on the test set below.
confusion(y_test, tree.predict(X_test), "Decision Tree (GINI)")Of 1987 Defaulters, the Decision Tree (GINI) identified 809
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | 0 | 1 |
|---|---|---|
| Actual | ||
| 0 | 5482 | 1280 |
| 1 | 1178 | 809 |
auroc = get_roc(tree, y_test, X_test, "Decision Tree (GINI)")
print(classification_report(y_test, tree.predict(X_test)))Optimal Threshold: 0.5

precision recall f1-score support
0 0.82 0.81 0.82 6762
1 0.39 0.41 0.40 1987
accuracy 0.72 8749
macro avg 0.61 0.61 0.61 8749
weighted avg 0.72 0.72 0.72 8749
tree2 = DecisionTreeClassifier(criterion = "entropy")
tree2.fit(X_train, y_train)
confusion(y_test, tree2.predict(X_test), "Decision Tree (Entropy)")Of 1987 Defaulters, the Decision Tree (Entropy) identified 831
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | 0 | 1 |
|---|---|---|
| Actual | ||
| 0 | 5509 | 1253 |
| 1 | 1156 | 831 |
get_roc(tree2, y_test, X_test, "Decision Tree (Entropy)")
print(classification_report(y_test, tree2.predict(X_test)))Optimal Threshold: 0.5

precision recall f1-score support
0 0.83 0.81 0.82 6762
1 0.40 0.42 0.41 1987
accuracy 0.72 8749
macro avg 0.61 0.62 0.61 8749
weighted avg 0.73 0.72 0.73 8749
There is negligible difference in using GINI or Entropy for decision trees. For the sake of simplicity, we will use GINI for the ensemble methods.
Random Forest is an ensemble method for the decision tree algorithm. It works by randomly choosing different features and data points to train multiple trees (that is, to form a forest) - and the resulting prediction is decided by the votes from all the trees.
Decision Trees are prone to overfitting on the training data, which reduces the performance on the test set. Random Forest mitigates this by training multiple trees. Random Forest is a form of bagging ensemble where the trees are trained concurrently.
To keep things consistent, our Random Forest classifier will also use the GINI Coefficient.
from sklearn.ensemble import RandomForestClassifier
randf = RandomForestClassifier(n_estimators=200)randf.fit(X_train, y_train)RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
print(classification_report(y_train, randf.predict(X_train))) precision recall f1-score support
0 1.00 1.00 1.00 13442
1 1.00 1.00 1.00 4054
accuracy 1.00 17496
macro avg 1.00 1.00 1.00 17496
weighted avg 1.00 1.00 1.00 17496
The training set has also been 100% correctly classified by the random forest model. Evaluating with the test set:
confusion(y_test, randf.predict(X_test), "Decision Tree (Random Forest)")Of 1987 Defaulters, the Decision Tree (Random Forest) identified 713
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | 0 | 1 |
|---|---|---|
| Actual | ||
| 0 | 6371 | 391 |
| 1 | 1274 | 713 |
auroc_rf = get_roc(randf, y_test, X_test, "Decision Tree (Random Forest)")
print(classification_report(y_test, randf.predict(X_test)))Optimal Threshold: 0.27

precision recall f1-score support
0 0.83 0.94 0.88 6762
1 0.65 0.36 0.46 1987
accuracy 0.81 8749
macro avg 0.74 0.65 0.67 8749
weighted avg 0.79 0.81 0.79 8749
The random forest ensemble performs much better than the decision tree alone. The accuracy and AUROC are both superior to the decision tree alone.
In this part we train a gradient boosted trees classifier. It is a boosting ensemble method for decision trees, which means that the trees are trained consecutively, where each new tree added is trained to correct the error from the previous tree.
For consistency our xgBoost ensemble will use n_estimators = 300 as we have done for the random forest ensemble.
from sklearn.ensemble import GradientBoostingClassifier
xgb = GradientBoostingClassifier(n_estimators=300, max_depth = 4)
xgb.fit(X_train, y_train)GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.1, loss='deviance', max_depth=4,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=300,
n_iter_no_change=None, presort='auto',
random_state=None, subsample=1.0, tol=0.0001,
validation_fraction=0.1, verbose=0,
warm_start=False)
print(classification_report(y_train, xgb.predict(X_train))) precision recall f1-score support
0 0.86 0.96 0.91 13442
1 0.79 0.46 0.58 4054
accuracy 0.85 17496
macro avg 0.82 0.71 0.74 17496
weighted avg 0.84 0.85 0.83 17496
We observe that the ensemble did not fully separate the data in the training set. (The default maximum depth is 3, so that might be a factor). Evaluating on the test set,
confusion(y_test, xgb.predict(X_test), "Decision Tree (Gradient Boosted Trees)")Of 1987 Defaulters, the Decision Tree (Gradient Boosted Trees) identified 717
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | 0 | 1 |
|---|---|---|
| Actual | ||
| 0 | 6381 | 381 |
| 1 | 1270 | 717 |
auroc = get_roc(xgb, y_test, X_test, "Decision Tree (XGBoost)")
print(classification_report(y_test, xgb.predict(X_test)))Optimal Threshold: 0.24738247273049666

From both the accuracy metrics and the AUROC, we observe that the gradient boosted tree performs similarly to the random forest classifier. We will choose Random Forest as our model of choice using the decision tree algorithm.
evaluation.loc[0] = (["Decision Trees - Random Forest" ,
classification_report(y_test, randf.predict(X_test), output_dict = True)["1"]["f1-score"],
auroc_rf])evaluation.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Model | F1-1 | AUROC | |
|---|---|---|---|
| 0 | Decision Trees - Random Forest | 0.461339 | 0.768458 |
Logistic regression is a regression technnique used to predict binary target variables. It works on the same principles as a linear regression model.
Our binary target (default vs non-default) can be expressed in terms of odds of defaulting, which is the ratio of the probability of default and probability of non-default.
In the logistic regression model, we log the odds (log-odds) and equate it to a weighted sum of regressors.

We then find weights for the regressors that best fits the data. Since the binary target (default or not) follows a bernoulli distribution, each data point has the following probability distribution function:

We would like to update p for each data point such that the log product (joint probability) of the above function for all data points is maximised. In other words, we are maximising the log-likelihood function.
The logistic regression equation produces a "squashed" curve like the one below. We then pick a cutoff value for the y axis to classify a data point as 0 (non-default) or 1 (default).

We will adopt a top-down approach for training our logistic regression model, i.e. include all regressors first and then remove the most insignificant ones at each iteration to achieve the best fit.
import statsmodels.api as smglm = sm.Logit(y_train,X_train).fit()
glm.summary()Warning: Maximum number of iterations has been exceeded.
Current function value: 0.444770
Iterations: 35
C:\Users\reonh\Anaconda3\lib\site-packages\statsmodels\base\model.py:512: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)
| Dep. Variable: | Y | No. Observations: | 17496 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 17450 |
| Method: | MLE | Df Model: | 45 |
| Date: | Fri, 22 Nov 2019 | Pseudo R-squ.: | 0.1784 |
| Time: | 00:13:23 | Log-Likelihood: | -7781.7 |
| converged: | False | LL-Null: | -9471.2 |
| Covariance Type: | nonrobust | LLR p-value: | 0.000 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| LIMIT_BAL | -0.8737 | 0.115 | -7.605 | 0.000 | -1.099 | -0.649 |
| SEX | -0.0964 | 0.041 | -2.343 | 0.019 | -0.177 | -0.016 |
| AGE | 0.2097 | 0.100 | 2.095 | 0.036 | 0.013 | 0.406 |
| PAY_0 | 0.6116 | 0.058 | 10.521 | 0.000 | 0.498 | 0.726 |
| PAY_2 | -0.5528 | 0.096 | -5.763 | 0.000 | -0.741 | -0.365 |
| PAY_3 | -0.2063 | 0.124 | -1.662 | 0.096 | -0.450 | 0.037 |
| PAY_4 | -0.2327 | 0.160 | -1.452 | 0.146 | -0.547 | 0.081 |
| PAY_5 | -0.0302 | 0.181 | -0.166 | 0.868 | -0.385 | 0.325 |
| PAY_6 | 0.4319 | 0.153 | 2.825 | 0.005 | 0.132 | 0.731 |
| BILL_AMT1 | -1.9057 | 0.554 | -3.442 | 0.001 | -2.991 | -0.821 |
| BILL_AMT2 | 1.1700 | 0.784 | 1.493 | 0.135 | -0.366 | 2.706 |
| BILL_AMT3 | 1.9680 | 0.729 | 2.700 | 0.007 | 0.540 | 3.396 |
| BILL_AMT4 | -0.4328 | 0.727 | -0.595 | 0.552 | -1.858 | 0.992 |
| BILL_AMT5 | -0.3910 | 0.882 | -0.443 | 0.658 | -2.120 | 1.338 |
| BILL_AMT6 | 0.2306 | 0.800 | 0.288 | 0.773 | -1.338 | 1.799 |
| PAY_AMT1 | -1.2427 | 0.308 | -4.041 | 0.000 | -1.845 | -0.640 |
| PAY_AMT2 | -1.8767 | 0.389 | -4.823 | 0.000 | -2.639 | -1.114 |
| PAY_AMT3 | -0.4002 | 0.299 | -1.339 | 0.181 | -0.986 | 0.186 |
| PAY_AMT4 | -0.5031 | 0.293 | -1.715 | 0.086 | -1.078 | 0.072 |
| PAY_AMT5 | -0.7629 | 0.295 | -2.589 | 0.010 | -1.341 | -0.185 |
| PAY_AMT6 | -0.6658 | 0.266 | -2.504 | 0.012 | -1.187 | -0.145 |
| MISSING-EDU | -14.2753 | 1898.465 | -0.008 | 0.994 | -3735.198 | 3706.648 |
| GRAD | 1.3518 | 0.220 | 6.148 | 0.000 | 0.921 | 1.783 |
| UNI | 1.3056 | 0.219 | 5.971 | 0.000 | 0.877 | 1.734 |
| HS | 1.2342 | 0.223 | 5.547 | 0.000 | 0.798 | 1.670 |
| MISSING-MS | -30.7439 | 1.14e+06 | -2.7e-05 | 1.000 | -2.23e+06 | 2.23e+06 |
| MARRIED | 0.0794 | 0.177 | 0.449 | 0.653 | -0.267 | 0.426 |
| SINGLE | -0.1024 | 0.177 | -0.577 | 0.564 | -0.450 | 0.245 |
| PAY_0_No_Transactions | -0.1746 | 0.123 | -1.415 | 0.157 | -0.416 | 0.067 |
| PAY_0_Pay_Duly | 0.0483 | 0.120 | 0.402 | 0.688 | -0.187 | 0.284 |
| PAY_0_Revolving_Credit | -0.9702 | 0.135 | -7.181 | 0.000 | -1.235 | -0.705 |
| PAY_2_No_Transactions | -1.4826 | 0.233 | -6.359 | 0.000 | -1.940 | -1.026 |
| PAY_2_Pay_Duly | -1.3804 | 0.221 | -6.244 | 0.000 | -1.814 | -0.947 |
| PAY_2_Revolving_Credit | -0.7926 | 0.226 | -3.514 | 0.000 | -1.235 | -0.350 |
| PAY_3_No_Transactions | -0.6881 | 0.297 | -2.317 | 0.021 | -1.270 | -0.106 |
| PAY_3_Pay_Duly | -0.7811 | 0.272 | -2.869 | 0.004 | -1.315 | -0.247 |
| PAY_3_Revolving_Credit | -0.7137 | 0.261 | -2.740 | 0.006 | -1.224 | -0.203 |
| PAY_4_No_Transactions | -0.9092 | 0.360 | -2.529 | 0.011 | -1.614 | -0.205 |
| PAY_4_Pay_Duly | -0.9199 | 0.341 | -2.699 | 0.007 | -1.588 | -0.252 |
| PAY_4_Revolving_Credit | -0.8088 | 0.331 | -2.442 | 0.015 | -1.458 | -0.160 |
| PAY_5_No_Transactions | -0.0741 | 0.401 | -0.185 | 0.853 | -0.860 | 0.711 |
| PAY_5_Pay_Duly | -0.2557 | 0.386 | -0.663 | 0.507 | -1.011 | 0.500 |
| PAY_5_Revolving_Credit | -0.2701 | 0.376 | -0.718 | 0.473 | -1.008 | 0.467 |
| PAY_6_No_Transactions | 0.6784 | 0.335 | 2.025 | 0.043 | 0.022 | 1.335 |
| PAY_6_Pay_Duly | 0.7000 | 0.328 | 2.134 | 0.033 | 0.057 | 1.343 |
| PAY_6_Revolving_Credit | 0.5159 | 0.320 | 1.615 | 0.106 | -0.110 | 1.142 |
print(classification_report(y_train,list(glm.predict(X_train)>0.5))) precision recall f1-score support
0 0.83 0.95 0.88 13442
1 0.67 0.36 0.47 4054
accuracy 0.81 17496
macro avg 0.75 0.65 0.68 17496
weighted avg 0.79 0.81 0.79 17496
The logisitc model with all features performs average on both the train and test set with an accuracy of about 0.8 but recall and f1 are still below 0.5. We will now try removing all the insignificant features to see how that affects the model performance.
#remove the most insignificant attribute, and retrain
train_log = X_train.copy()
glm = sm.Logit(y_train,train_log).fit()
while max(glm.pvalues) > 0.01:
least = glm.pvalues[glm.pvalues == max(glm.pvalues)].index[0]
train_log = train_log.drop(least,axis = 1)
glm = sm.Logit(y_train,train_log).fit()
glm.summary() Warning: Maximum number of iterations has been exceeded.
Current function value: 0.444770
Iterations: 35
C:\Users\reonh\Anaconda3\lib\site-packages\statsmodels\base\model.py:512: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)
Warning: Maximum number of iterations has been exceeded.
Current function value: 0.445360
Iterations: 35
Optimization terminated successfully.
Current function value: 0.445386
Iterations 7
Optimization terminated successfully.
Current function value: 0.445386
Iterations 7
Optimization terminated successfully.
Current function value: 0.445387
Iterations 7
C:\Users\reonh\Anaconda3\lib\site-packages\statsmodels\base\model.py:512: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
"Check mle_retvals", ConvergenceWarning)
Optimization terminated successfully.
Current function value: 0.445388
Iterations 7
Optimization terminated successfully.
Current function value: 0.445392
Iterations 7
Optimization terminated successfully.
Current function value: 0.445397
Iterations 7
Optimization terminated successfully.
Current function value: 0.445410
Iterations 7
Optimization terminated successfully.
Current function value: 0.445455
Iterations 7
Optimization terminated successfully.
Current function value: 0.445512
Iterations 7
Optimization terminated successfully.
Current function value: 0.445596
Iterations 7
Optimization terminated successfully.
Current function value: 0.445680
Iterations 7
Optimization terminated successfully.
Current function value: 0.445770
Iterations 7
Optimization terminated successfully.
Current function value: 0.445853
Iterations 7
Optimization terminated successfully.
Current function value: 0.445877
Iterations 7
Optimization terminated successfully.
Current function value: 0.445963
Iterations 7
Optimization terminated successfully.
Current function value: 0.446090
Iterations 7
Optimization terminated successfully.
Current function value: 0.446288
Iterations 7
| Dep. Variable: | Y | No. Observations: | 17496 |
|---|---|---|---|
| Model: | Logit | Df Residuals: | 17468 |
| Method: | MLE | Df Model: | 27 |
| Date: | Fri, 22 Nov 2019 | Pseudo R-squ.: | 0.1756 |
| Time: | 00:14:16 | Log-Likelihood: | -7808.3 |
| converged: | True | LL-Null: | -9471.2 |
| Covariance Type: | nonrobust | LLR p-value: | 0.000 |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| LIMIT_BAL | -0.8984 | 0.113 | -7.922 | 0.000 | -1.121 | -0.676 |
| SEX | -0.1153 | 0.041 | -2.847 | 0.004 | -0.195 | -0.036 |
| PAY_0 | 0.6189 | 0.037 | 16.520 | 0.000 | 0.545 | 0.692 |
| PAY_2 | -0.5692 | 0.088 | -6.463 | 0.000 | -0.742 | -0.397 |
| PAY_3 | -0.2710 | 0.082 | -3.313 | 0.001 | -0.431 | -0.111 |
| PAY_6 | 0.2151 | 0.031 | 6.899 | 0.000 | 0.154 | 0.276 |
| BILL_AMT1 | -1.3934 | 0.368 | -3.784 | 0.000 | -2.115 | -0.672 |
| BILL_AMT3 | 2.0154 | 0.435 | 4.638 | 0.000 | 1.164 | 2.867 |
| PAY_AMT1 | -1.2565 | 0.287 | -4.371 | 0.000 | -1.820 | -0.693 |
| PAY_AMT2 | -2.1865 | 0.376 | -5.816 | 0.000 | -2.923 | -1.450 |
| PAY_AMT5 | -0.8702 | 0.265 | -3.279 | 0.001 | -1.390 | -0.350 |
| PAY_AMT6 | -0.7982 | 0.266 | -3.000 | 0.003 | -1.320 | -0.277 |
| GRAD | 1.3465 | 0.175 | 7.687 | 0.000 | 1.003 | 1.690 |
| UNI | 1.2982 | 0.174 | 7.462 | 0.000 | 0.957 | 1.639 |
| HS | 1.2384 | 0.178 | 6.960 | 0.000 | 0.890 | 1.587 |
| MARRIED | 0.2359 | 0.042 | 5.643 | 0.000 | 0.154 | 0.318 |
| PAY_0_Revolving_Credit | -0.9811 | 0.093 | -10.583 | 0.000 | -1.163 | -0.799 |
| PAY_2_No_Transactions | -1.5901 | 0.220 | -7.230 | 0.000 | -2.021 | -1.159 |
| PAY_2_Pay_Duly | -1.4026 | 0.200 | -7.010 | 0.000 | -1.795 | -1.010 |
| PAY_2_Revolving_Credit | -0.8163 | 0.202 | -4.051 | 0.000 | -1.211 | -0.421 |
| PAY_3_No_Transactions | -0.8432 | 0.228 | -3.701 | 0.000 | -1.290 | -0.397 |
| PAY_3_Pay_Duly | -0.8926 | 0.196 | -4.566 | 0.000 | -1.276 | -0.509 |
| PAY_3_Revolving_Credit | -0.8227 | 0.179 | -4.586 | 0.000 | -1.174 | -0.471 |
| PAY_4_No_Transactions | -0.4537 | 0.143 | -3.172 | 0.002 | -0.734 | -0.173 |
| PAY_4_Pay_Duly | -0.5711 | 0.107 | -5.328 | 0.000 | -0.781 | -0.361 |
| PAY_4_Revolving_Credit | -0.4353 | 0.075 | -5.806 | 0.000 | -0.582 | -0.288 |
| PAY_6_No_Transactions | 0.3028 | 0.089 | 3.399 | 0.001 | 0.128 | 0.477 |
| PAY_6_Pay_Duly | 0.2489 | 0.078 | 3.197 | 0.001 | 0.096 | 0.402 |
count = len(glm.pvalues.index)
print(str(count) + " Columns left:")
print(glm.pvalues.index)28 Columns left:
Index(['LIMIT_BAL', 'SEX', 'PAY_0', 'PAY_2', 'PAY_3', 'PAY_6', 'BILL_AMT1',
'BILL_AMT3', 'PAY_AMT1', 'PAY_AMT2', 'PAY_AMT5', 'PAY_AMT6', 'GRAD',
'UNI', 'HS', 'MARRIED', 'PAY_0_Revolving_Credit',
'PAY_2_No_Transactions', 'PAY_2_Pay_Duly', 'PAY_2_Revolving_Credit',
'PAY_3_No_Transactions', 'PAY_3_Pay_Duly', 'PAY_3_Revolving_Credit',
'PAY_4_No_Transactions', 'PAY_4_Pay_Duly', 'PAY_4_Revolving_Credit',
'PAY_6_No_Transactions', 'PAY_6_Pay_Duly'],
dtype='object')
print(classification_report(y_test,list(glm.predict(X_test[glm.pvalues.index])>0.5))) precision recall f1-score support
0 0.83 0.95 0.89 6762
1 0.68 0.36 0.47 1987
accuracy 0.82 8749
macro avg 0.76 0.65 0.68 8749
weighted avg 0.80 0.82 0.79 8749
Since there is not much change to the model performance on both the train and test set when we reduce the features, we will use the reduced logistic regression model from this point onwards (Principle of Parsimony).
We now Calculate the AUROC for the train set.
optimal_log = get_optimal(glm, y_train, X_train[glm.pvalues.index], "Logistic Regression")
get_roc(glm, y_train, X_train[glm.pvalues.index], "Logistic Regression")
print(classification_report(y_test,list(glm.predict(X_test[glm.pvalues.index])> optimal_log)))Optimal Threshold: 0.21650864211883647

precision recall f1-score support
0 0.88 0.78 0.83 6762
1 0.46 0.62 0.53 1987
accuracy 0.75 8749
macro avg 0.67 0.70 0.68 8749
weighted avg 0.78 0.75 0.76 8749
Since the optimal cut off was found to be ~0.22 using the training data, we used that as our cut off for our evaluation of the test set.
Unfortunately, the training accuracy has gone down when we used the optimal cutoff. However, accuracy may be misleading in a dataset like ours where most of the targets are non-defaults.
The recall here is more important - detecting defaulters is more useful than detecting non-defaulters. With a higher recall, our model with lower cutoff is able to correctly catch more defaulters. We note that this increase in recall is greater than the increase in F-1.
Calculate the confusion matrices for both cut offs to better compare their performance.
confusion(y_test,glm.predict(X_test[glm.pvalues.index])>optimal_log, "Logistic Regression")Of 1987 Defaulters, the Logistic Regression identified 1235
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | False | True |
|---|---|---|
| Actual | ||
| 0 | 5303 | 1459 |
| 1 | 752 | 1235 |
confusion(y_test,glm.predict(X_test[glm.pvalues.index])>0.50, "Logistic Regression")Of 1987 Defaulters, the Logistic Regression identified 715
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | False | True |
|---|---|---|
| Actual | ||
| 0 | 6421 | 341 |
| 1 | 1272 | 715 |
It is evident that the lower cutoff is better able to detect defaults.
auroc = get_roc(glm, y_test, X_test[glm.pvalues.index], "Logistic Regression")Optimal Threshold: 0.24907536768337235

evaluation.loc[1] = ["Logistic Regression (Optimal Cutoff)" ,
classification_report(y_test,list(glm.predict(X_test[glm.pvalues.index])>optimal_log), output_dict = True)["1"]["f1-score"],
auroc]evaluation.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Model | F1-1 | AUROC | |
|---|---|---|---|
| 0 | Decision Trees - Random Forest | 0.461339 | 0.768458 |
| 1 | Logistic Regression (Optimal Cutoff) | 0.527665 | 0.765244 |
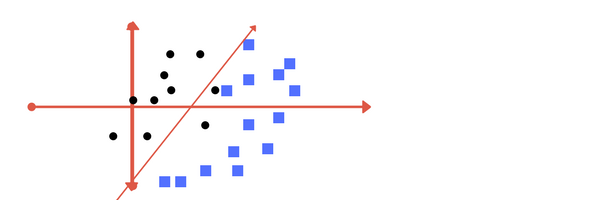
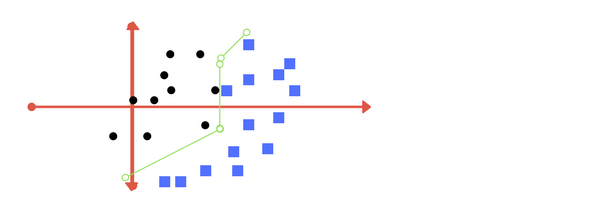
Support vector machines attempt to find an optimal hyperplane that is able to separate the two classes in n-dimensional space. This is done by finding the hyperplane that maximises the distance between itself and support vectors (data points that lie closest to the decision boundary).

Given a training dataset of form (X,Y), where X is a vector of attributes of the sample, and where Y are either 1 or -1, each indicating the class to which the point X belongs. We want to find the "maximum-margin hyperplane" that divides the group of points X which Y = 1 from the group of points for which Y = -1, which is defined so that the distance between the hyperplane and the nearest point X from either group is maximized.
Any hyperplane can be written as the set of points X satisfying

|
where W is the (not necessarily normalized) normal vector to the hyperplane. This is much like Hesse normal form, except that W is not necessarily a unit vector. The parameter b/||W|| determines the offset of the hyperplane from the origin along the normal vector W.
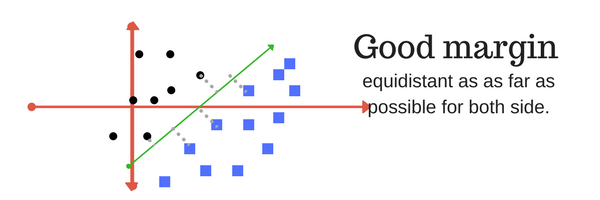
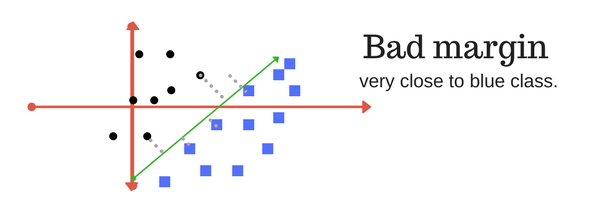
A margin is a separation of line to the closest class points. Very importrant characteristic of SVM classifier. SVM to core tries to achieve a good margin. A good margin is one where this separation is larger for both the classes. Images below gives to visual example of good and bad margin. A good margin allows the points to be in their respective classes without crossing to other class.
 |
 |
Our goal is to maximize the margin. Among all possible hyperplanes meeting the constraints, we will choose the hyperplane with the smallest ‖w‖ because it is the one which will have the biggest margin.
If the training data is linearly separable, we can select two parallel hyperplanes that separate the two classes of data, so that the distance between them is as large as possible. The region bounded by these two hyperplanes is called the "margin", and the maximum-margin hyperplane is the hyperplane that lies halfway between them. With a normalized or standardized dataset, these hyperplanes can be described by an equation and we can put this together to get the optimization problem:
Minimize ||W|| subject to:

|
Often, the data are not linearly separable. Thus, to extend SVM to cases in which the data are not linearly separable, we introduce the hinge loss function,

|
This function is zero if the constraint in (1) is satisfied, in other words, if Xlies on the correct side of the margin. For data on the wrong side of the margin, the function's value is proportional to the distance from the margin.
We then wish to minimize

|
where the parameter lambda determines the trade-off between increasing the margin size and ensuring that the X lie on the correct side of the margin. Thus, for sufficiently small values of lambda , the second term in the loss function will become negligible, hence, it will behave similar to the hard-margin SVM, if the input data are linearly classifiable, but will still learn if a classification rule is viable or not.
We focus on the soft-margin classifier since, as noted above, choosing a sufficiently small value for lambda yields the hard-margin classifier for linearly classifiable input data. The classical approach, which involves reducing (2) to a quadratic programming problem, is detailed below.
Minimizing (2) can be rewritten as a constrained optimization problem with a differentiable objective function in the following way.
We can rewrite the optimization problem as follows

|
This is called the primal problem.
By solving for the Lagrangian dual of the above problem, one obtains the simplified problem

|

|
Here, the variables C are defined such that

|
For a dataset that is non-linearly separable, a way is to create nonlinear classifiers by applying the kernel trick to maximum-margin hyperplanes. The resulting algorithm is formally similar, except that every dot product is replaced by a nonlinear kernel function. This allows the algorithm to fit the maximum-margin hyperplane in a transformed feature space. The transformation may be nonlinear and the transformed space high-dimensional; although the classifier is a hyperplane in the transformed feature space, it may be nonlinear in the original input space.
Generally, Linear Kernel is the best choice as SVM is already a linear model and has the lowest computational complexity. More often, if the dataset is not linearly separable, Radial Basis Function is the next most common kernel to be used.
The Regularization parameter (often termed as C parameter in python’s sklearn library) tells the SVM optimization how much you want to avoid misclassifying each training example.
For large values of C, the optimization will choose a smaller-margin hyperplane if that hyperplane does a better job of getting all the training points classified correctly. Conversely, a very small value of C will cause the optimizer to look for a larger-margin separating hyperplane, even if that hyperplane misclassifies more points.
 |
 |
The tradeoff is however, a larger value of C might result in overfitting of the model, which is undersirable as it does not generalise the model for other data sets. Consequently, a smaller value of C might result in too many misclassified data points, which means that the model is low in accuracy in the first place. Thus, choosing the right balance of the C value is important.
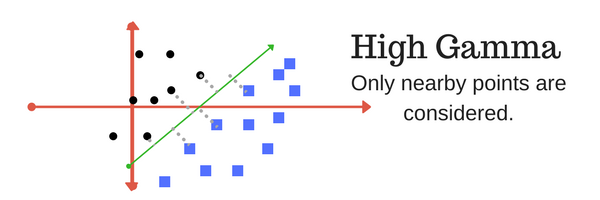
The gamma parameter defines how far the influence of a single training example reaches, with low values meaning ‘far’ and high values meaning ‘close’. In other words, with low gamma, points far away from plausible separation line are considered in the calculation for the separation line. Where as high gamma means the points close to plausible line are considered in the calculation.
 |
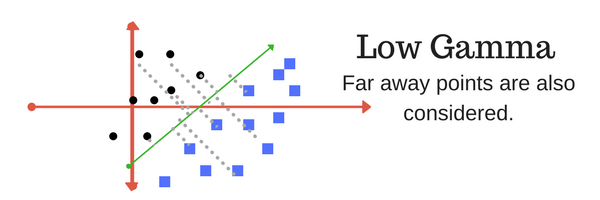 |
Similarly to regularization, there is a tradeoff between high and low values of Gamma. Higher values of Gamma may result in too strict rules and thus the model cannot find a linearly separable line. Whereas lower values of Gamma may result in including too much noise into the model by including further away points, which reduces the model accuracy. Thus, finding the right balance of Gamma is also important.
For this dataset, we will perform SVM to the model and access its accuracy progressively, starting from no parameter tuning.
First, we train our SVM model without parameter tuning. Note that the default kernel for sklearn svm is "rbf" and cost = 1.0 and gamma = 1/n where n is the number of samples.
from sklearn import svm
#train svm model without standardization and no parameter tuning
clf_original = svm.SVC( probability = True, gamma = 'scale')
clf_original.fit(X_train, y_train)SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='scale', kernel='rbf',
max_iter=-1, probability=True, random_state=None, shrinking=True, tol=0.001,
verbose=False)
#plot roc for svm
get_roc(clf_original, y_test, X_test, "SVM default parameters")
print(classification_report(y_test, clf_original.predict(X_test)))Optimal Threshold: 0.16469105377809068

precision recall f1-score support
0 0.83 0.95 0.89 6762
1 0.68 0.36 0.47 1987
accuracy 0.82 8749
macro avg 0.76 0.66 0.68 8749
weighted avg 0.80 0.82 0.79 8749
#confusion matrix
confusion(y_test,clf_original.predict(X_test), "SVM default parameters")Of 1987 Defaulters, the SVM default parameters identified 713
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | 0 | 1 |
|---|---|---|
| Actual | ||
| 0 | 6432 | 330 |
| 1 | 1274 | 713 |
Based on AUROC and Recall, the SVM model with default parameters seem to do average compared to the other models tested. Now let's search for the best parameters to tune the model.
One way to find the best parameters for the model is using grid search via GridSearchCV package from sklearn.
Grid search is the process of performing hyper parameter tuning in order to determine the optimal values for a given model. This is significant as the performance of the entire model is based on the hyper parameter values specified.
GridSearchSV works by using a cross validation process to determine the hyper parameter value set which provides the best accuracy levels. We will start with the linear kernel and move on to rbf if necessary.
from sklearn.model_selection import GridSearchCV
def svc_param_selection(X, y, nfolds):
Cs = [0.01, 0.1, 1]
gammas = [0.01, 0.1, 1]
param_grid = {'C': Cs, 'gamma' : gammas}
grid_search = GridSearchCV(svm.SVC(kernel='linear'), param_grid, cv=nfolds, scoring = 'recall')
grid_search.fit(X, y)
grid_search.best_params_
return grid_search.best_params_
svc_param_selection(X_train, y_train,2){'C': 0.01, 'gamma': 0.01}
With 5 folds, it can be found that C = 0.01 , and gamma = 0.01 will have the best svm model with kernel
#train svm model with feature reduction and cost = 0.01, gamma = 0.01, linear kernel
clf_reduced_tuned = svm.SVC(kernel = 'linear', probability = True, C = 0.01, gamma = 0.01 )
clf_reduced_tuned.fit(X_train, y_train)SVC(C=0.01, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.01, kernel='linear',
max_iter=-1, probability=True, random_state=None, shrinking=True, tol=0.001,
verbose=False)
auroc = get_roc(clf_reduced_tuned, y_test, X_test,
"SVM reduced features and tuning linear kernel")
print(classification_report(y_test, clf_reduced_tuned.predict(X_test)))Optimal Threshold: 0.15996357777982226

precision recall f1-score support
0 0.83 0.96 0.89 6762
1 0.70 0.32 0.44 1987
accuracy 0.81 8749
macro avg 0.77 0.64 0.66 8749
weighted avg 0.80 0.81 0.79 8749
#confusion matrix
confusion(y_test,clf_reduced_tuned.predict(X_test), "SVM reduced features and tuning linear kernal")Of 1987 Defaulters, the SVM reduced features and tuning linear kernal identified 638
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Predicted | 0 | 1 |
|---|---|---|
| Actual | ||
| 0 | 6492 | 270 |
| 1 | 1349 | 638 |
As shown, the AUROC actually increased with tuning of parameters. Next, we will experiment with the RBF kernel
#train svm model with feature reduction and cost = 0.1, gamma = 0.1, rbf kernel
clf_reduced_tuned_rbf = svm.SVC(kernel = 'rbf', probability = True, C = 0.1, gamma = 0.1)
clf_reduced_tuned_rbf.fit(X_train, y_train)SVC(C=0.1, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.1, kernel='rbf',
max_iter=-1, probability=True, random_state=None, shrinking=True, tol=0.001,
verbose=False)
auroc = get_roc(clf_reduced_tuned_rbf, y_test, X_test,
"SVM reduced features and tuning rbf kernel")
print(classification_report(y_test, clf_reduced_tuned_rbf.predict(X_test)))Optimal Threshold: 0.15910713557498266

precision recall f1-score support
0 0.84 0.95 0.89 6762
1 0.67 0.38 0.48 1987
accuracy 0.82 8749
macro avg 0.76 0.66 0.69 8749
weighted avg 0.80 0.82 0.80 8749
As shown, the rbf kernel increases the AUROC and the recall increased to 0.40, thus, it can be said that the rbf kernel is better than the linear kernel. We will choose the RBF SVM as our best performing support vector machine.
evaluation.loc[2] = (["SVM-RBF (Grid Search)" ,
classification_report(y_test, clf_reduced_tuned_rbf.predict(X_test), output_dict = True)["1"]["f1-score"],
auroc])
evaluation.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Model | F1-1 | AUROC | |
|---|---|---|---|
| 0 | Decision Trees - Random Forest | 0.461339 | 0.768458 |
| 1 | Logistic Regression (Optimal Cutoff) | 0.527665 | 0.765244 |
| 2 | SVM-RBF (Grid Search) | 0.482247 | 0.748465 |
We will now apply the best selected kernel (linear kernel) on filtered features to access AUROC and recall.
clf_reduced_tuned_filtered = svm.SVC(kernel = 'rbf', probability = True)
clf_reduced_tuned_filtered.fit(X_train_filter, y_train)C:\Users\reonh\Anaconda3\lib\site-packages\sklearn\svm\base.py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning.
"avoid this warning.", FutureWarning)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='rbf', max_iter=-1, probability=True, random_state=None,
shrinking=True, tol=0.001, verbose=False)
get_roc(clf_reduced_tuned_filtered, y_test, X_test_filter,
"SVM reduced features and tuning linear kernel")Optimal Threshold: 0.16104553371241384

0.6689738476077944
print(classification_report(y_test, clf_reduced_tuned_filtered.predict(X_test_filter))) precision recall f1-score support
0 0.84 0.95 0.89 6762
1 0.67 0.37 0.48 1987
accuracy 0.82 8749
macro avg 0.75 0.66 0.68 8749
weighted avg 0.80 0.82 0.79 8749
As we can see, the performance is not as great after using filtered features. The AUROC decreased while the recall remained the same. Thus, we will stick to using unfiltered features and SVM with rbf kernel.
We will now use the train and test sets as defined above and attempt to implement a neural network model on the data
A neural network is comprised of many layers of perceptrons that take in a vector as input and outputs a value. The outputs from one layer of perceptrons are passed into the next layer of perceptrons as input, until we reach the output layer. Each perceptron combines its input via an activation function.
.

The network is at first randomly initialised with random weights on all its layers. Training samples are then passed into the network and predictions are made. The training error (difference between the actual value and the predicted value) is used to recalibrate the neural network by changing the weights. The change in weights is found via gradient descent, and then backpropogated through the neural network to update all layers.
This process is repeated iteratively until the model converges (i.e. it cannot be improved further).
Here we create an instance of our model, specifically a Sequential model, and add layers one at a time until we are happy with our network architecture. We will be training the model on our feature-selected dataset to speed up computation by reducing dimensionality. We have found that the performance difference between the 2 datasets are negligible.
We ensure the input layer has the right number of input features, and is specified when creating the first layer with the input_dim argument and setting it to 17 (The size of the feature selected dataset). Additionaly, we start off using a fully-connected network structure with three layers, and attempt to increase the number of layers at later part ater fully optimising our model.
Fully connected layers are defined using the Dense class. We specify the number of neurons or nodes in the layer as the first argument, and specify the activation function using the activation argument. The rectified linear unit activation function (Relu) is usedon the first two layers and the Sigmoid function in the output layer.
Conventionally, Sigmoid and Tanh activation functions were preferred for all layers. However, better performance is achieved using the ReLU activation function. We use a sigmoid on the output layer to ensure our network output is between 0 and 1 and easy to map (binary) to either a probability of class 1 or snap to a hard classification of either class with a default threshold of 0.5.
The model expects rows of data with 17 variables (the input_dim=17 argument) The first hidden layer has 17 nodes and uses the relu activation function. The second hidden layer has 17 nodes and uses the relu activation function. The output layer has one node and uses the sigmoid activation function.
The model uses the efficient numerical libraries as the backend, and in this case Tensorflow is used. The backend automatically chooses the best way to represent the network for training and making predictions to run.
We must specify the loss function to use to evaluate a set of weights, the optimizer is used to search through different weights for the network and any optional metrics we would like to collect and report during training.
After experimenting with the various loss functions, such as hinge loss and binary cross entropy, we found that entropy performed the best for our dataset.
We have also found that among all the optimizers (Adam, SGD, RMSprop, Adagrad, Adadelta, Adamax and Nadam) the optimizer "adam" is the most efficient yet yields the best results.
Additionaly, for this problem, we will run for a small number of epochs (20) and use a relatively small batch size of 10. This means that each epoch will involve (20/10) 2 updates to the model weights. After we have finalised the best optimizer, we will then increase the numebr of epochs to increase the number of updates to obtain a better result.
from numpy import loadtxt
from keras.models import Sequential
from keras.layers import Dense
# optimisers to try: Adam, SGD, RMSprop, Adagrad, Adadelta, Adamax and Nadam
# verdict : Adam
# Loss function to try: Binary Cross Entropy, Hinge, Logcosh
# verdict: Binary Cross Entropy
# define the keras model
model = Sequential()
model.add(Dense(12, input_dim=17, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train_filter, y_train, epochs=20, batch_size=10)Using TensorFlow backend.
Epoch 1/20
17496/17496 [==============================] - 2s 110us/step - loss: 0.4708 - accuracy: 0.7956
Epoch 2/20
17496/17496 [==============================] - 2s 107us/step - loss: 0.4502 - accuracy: 0.8116
Epoch 3/20
17496/17496 [==============================] - 2s 113us/step - loss: 0.4477 - accuracy: 0.8125
Epoch 4/20
17496/17496 [==============================] - 2s 96us/step - loss: 0.4461 - accuracy: 0.8130
Epoch 5/20
17496/17496 [==============================] - 2s 105us/step - loss: 0.4450 - accuracy: 0.8133
Epoch 6/20
17496/17496 [==============================] - 2s 109us/step - loss: 0.4443 - accuracy: 0.81450s - loss: 0.4424 -
Epoch 7/20
17496/17496 [==============================] - 2s 96us/step - loss: 0.4437 - accuracy: 0.8150
Epoch 8/20
17496/17496 [==============================] - 2s 101us/step - loss: 0.4435 - accuracy: 0.8144
Epoch 9/20
17496/17496 [==============================] - 2s 103us/step - loss: 0.4433 - accuracy: 0.8147
Epoch 10/20
17496/17496 [==============================] - 2s 101us/step - loss: 0.4429 - accuracy: 0.8142
Epoch 11/20
17496/17496 [==============================] - 2s 118us/step - loss: 0.4418 - accuracy: 0.8132
Epoch 12/20
17496/17496 [==============================] - 2s 112us/step - loss: 0.4416 - accuracy: 0.81450s - loss: 0.4413 - accuracy:
Epoch 13/20
17496/17496 [==============================] - 2s 97us/step - loss: 0.4419 - accuracy: 0.8138
Epoch 14/20
17496/17496 [==============================] - 2s 128us/step - loss: 0.4417 - accuracy: 0.8140
Epoch 15/20
17496/17496 [==============================] - 2s 115us/step - loss: 0.4415 - accuracy: 0.8142
Epoch 16/20
17496/17496 [==============================] - 2s 118us/step - loss: 0.4415 - accuracy: 0.8141
Epoch 17/20
17496/17496 [==============================] - 2s 108us/step - loss: 0.4409 - accuracy: 0.8152
Epoch 18/20
17496/17496 [==============================] - 2s 127us/step - loss: 0.4413 - accuracy: 0.8145
Epoch 19/20
17496/17496 [==============================] - 2s 126us/step - loss: 0.4403 - accuracy: 0.8145
Epoch 20/20
17496/17496 [==============================] - 2s 110us/step - loss: 0.4405 - accuracy: 0.8156
<keras.callbacks.callbacks.History at 0x17a5fc89b38>
get_roc(model, y_test, X_test_filter, "Neural Network 17x8x8x1 Adam, Entropy, 20 epoch")
predictions = list(model.predict(X_test_filter).ravel() > 0.5)
print(classification_report(y_test,predictions))Optimal Threshold: 0.23287344

precision recall f1-score support
0 0.84 0.94 0.89 6762
1 0.65 0.39 0.49 1987
accuracy 0.81 8749
macro avg 0.75 0.66 0.69 8749
weighted avg 0.80 0.81 0.80 8749
Experimenting with lowering the cutoff for the neural network,
optimal_adam = get_optimal(model, y_train, X_train_filter, "Neural Network 17x8x8x1 Adam Entropy")
auroc = get_roc(model, y_test, X_test_filter, "Neural Network 17x8x8x1 Adam, Entropy")
predictions = list(model.predict(X_test_filter).ravel() > optimal_adam)
print(classification_report(y_test,predictions))Optimal Threshold: 0.23287344

precision recall f1-score support
0 0.87 0.81 0.84 6762
1 0.48 0.60 0.54 1987
accuracy 0.76 8749
macro avg 0.68 0.71 0.69 8749
weighted avg 0.79 0.76 0.77 8749
The performance is quite impressive when we lowered the classification cut off. The ROC of 0.76 is also on par with other models. Now we ramp up the number of epochs.
model50 = Sequential()
model50.add(Dense(12, input_dim=17, activation='relu'))
model50.add(Dense(8, activation='relu'))
model50.add(Dense(8, activation='relu'))
model50.add(Dense(8, activation='relu'))
model50.add(Dense(1, activation='sigmoid'))
# compile the keras model
model50.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit the keras model on the dataset
model50.fit(X_train_filter, y_train, epochs=50, batch_size=10)Epoch 1/50
17496/17496 [==============================] - 2s 112us/step - loss: 0.4863 - accuracy: 0.7969
Epoch 2/50
17496/17496 [==============================] - 2s 102us/step - loss: 0.4511 - accuracy: 0.8122
Epoch 3/50
17496/17496 [==============================] - 2s 103us/step - loss: 0.4485 - accuracy: 0.8124
Epoch 4/50
17496/17496 [==============================] - 2s 105us/step - loss: 0.4472 - accuracy: 0.81200s - loss: 0.4465
Epoch 5/50
17496/17496 [==============================] - 2s 103us/step - loss: 0.4461 - accuracy: 0.8123
Epoch 6/50
17496/17496 [==============================] - 2s 119us/step - loss: 0.4450 - accuracy: 0.8124
Epoch 7/50
17496/17496 [==============================] - 2s 112us/step - loss: 0.4432 - accuracy: 0.8138
Epoch 8/50
17496/17496 [==============================] - 2s 103us/step - loss: 0.4428 - accuracy: 0.8139
Epoch 9/50
17496/17496 [==============================] - 2s 104us/step - loss: 0.4422 - accuracy: 0.8132
Epoch 10/50
17496/17496 [==============================] - 2s 101us/step - loss: 0.4420 - accuracy: 0.8140
Epoch 11/50
17496/17496 [==============================] - 2s 97us/step - loss: 0.4411 - accuracy: 0.8137
Epoch 12/50
17496/17496 [==============================] - 2s 104us/step - loss: 0.4410 - accuracy: 0.8146
Epoch 13/50
17496/17496 [==============================] - 2s 97us/step - loss: 0.4412 - accuracy: 0.8143
Epoch 14/50
17496/17496 [==============================] - 2s 98us/step - loss: 0.4415 - accuracy: 0.8141
Epoch 15/50
17496/17496 [==============================] - 2s 120us/step - loss: 0.4402 - accuracy: 0.8149
Epoch 16/50
17496/17496 [==============================] - 2s 103us/step - loss: 0.4402 - accuracy: 0.8146
Epoch 17/50
17496/17496 [==============================] - 2s 100us/step - loss: 0.4406 - accuracy: 0.8141
Epoch 18/50
17496/17496 [==============================] - 2s 110us/step - loss: 0.4400 - accuracy: 0.8152
Epoch 19/50
17496/17496 [==============================] - 2s 102us/step - loss: 0.4397 - accuracy: 0.8140
Epoch 20/50
17496/17496 [==============================] - 2s 100us/step - loss: 0.4398 - accuracy: 0.8140
Epoch 21/50
17496/17496 [==============================] - 2s 104us/step - loss: 0.4396 - accuracy: 0.8153
Epoch 22/50
17496/17496 [==============================] - 2s 101us/step - loss: 0.4401 - accuracy: 0.8138
Epoch 23/50
17496/17496 [==============================] - 2s 112us/step - loss: 0.4394 - accuracy: 0.8150
Epoch 24/50
17496/17496 [==============================] - 2s 119us/step - loss: 0.4397 - accuracy: 0.8152
Epoch 25/50
17496/17496 [==============================] - 2s 117us/step - loss: 0.4396 - accuracy: 0.8148
Epoch 26/50
17496/17496 [==============================] - 2s 106us/step - loss: 0.4396 - accuracy: 0.8144
Epoch 27/50
17496/17496 [==============================] - 2s 95us/step - loss: 0.4393 - accuracy: 0.8135
Epoch 28/50
17496/17496 [==============================] - 2s 100us/step - loss: 0.4390 - accuracy: 0.8152
Epoch 29/50
17496/17496 [==============================] - 2s 115us/step - loss: 0.4392 - accuracy: 0.8138
Epoch 30/50
17496/17496 [==============================] - 2s 100us/step - loss: 0.4391 - accuracy: 0.8141
Epoch 31/50
17496/17496 [==============================] - 2s 102us/step - loss: 0.4397 - accuracy: 0.8149
Epoch 32/50
17496/17496 [==============================] - 2s 127us/step - loss: 0.4390 - accuracy: 0.8147
Epoch 33/50
17496/17496 [==============================] - 2s 115us/step - loss: 0.4388 - accuracy: 0.8145
Epoch 34/50
17496/17496 [==============================] - 2s 115us/step - loss: 0.4385 - accuracy: 0.8153
Epoch 35/50
17496/17496 [==============================] - 2s 102us/step - loss: 0.4389 - accuracy: 0.8150
Epoch 36/50
17496/17496 [==============================] - 2s 100us/step - loss: 0.4391 - accuracy: 0.8146
Epoch 37/50
17496/17496 [==============================] - 2s 107us/step - loss: 0.4386 - accuracy: 0.8142
Epoch 38/50
17496/17496 [==============================] - 2s 102us/step - loss: 0.4386 - accuracy: 0.8143
Epoch 39/50
17496/17496 [==============================] - 2s 101us/step - loss: 0.4379 - accuracy: 0.8148
Epoch 40/50
17496/17496 [==============================] - 2s 110us/step - loss: 0.4385 - accuracy: 0.8148
Epoch 41/50
17496/17496 [==============================] - 2s 116us/step - loss: 0.4386 - accuracy: 0.8149
Epoch 42/50
17496/17496 [==============================] - 2s 104us/step - loss: 0.4380 - accuracy: 0.8150
Epoch 43/50
17496/17496 [==============================] - 2s 108us/step - loss: 0.4382 - accuracy: 0.8144
Epoch 44/50
17496/17496 [==============================] - 2s 101us/step - loss: 0.4381 - accuracy: 0.8152
Epoch 45/50
17496/17496 [==============================] - 2s 105us/step - loss: 0.4378 - accuracy: 0.8151
Epoch 46/50
17496/17496 [==============================] - 2s 104us/step - loss: 0.4374 - accuracy: 0.8153
Epoch 47/50
17496/17496 [==============================] - 2s 99us/step - loss: 0.4382 - accuracy: 0.8152
Epoch 48/50
17496/17496 [==============================] - 2s 110us/step - loss: 0.4379 - accuracy: 0.8166
Epoch 49/50
17496/17496 [==============================] - 2s 112us/step - loss: 0.4381 - accuracy: 0.8144
Epoch 50/50
17496/17496 [==============================] - 2s 109us/step - loss: 0.4378 - accuracy: 0.8154
<keras.callbacks.callbacks.History at 0x17a5fe12630>
We observe that the accuracy did not increase much at all from the 20th to 50th epoch. In such a situation we will choose the 20 epoch model for its faster computation.
optimal_adam50 = get_optimal(model50, y_train, X_train_filter, "Neural Network 17x8x8x1 Adam Entropy")
get_roc(model50, y_test, X_test_filter, "Neural Network 17x8x8x1 Adam, Entropy, 50 epoch")
predictions50 = list(model50.predict(X_test_filter).ravel() > optimal_adam50)
print(classification_report(y_test,predictions50))Optimal Threshold: 0.20843479

precision recall f1-score support
0 0.87 0.82 0.84 6762
1 0.48 0.59 0.53 1987
accuracy 0.76 8749
macro avg 0.68 0.70 0.69 8749
weighted avg 0.78 0.76 0.77 8749
evaluation.loc[3] = (["Neural Network - 17x8x8x1 Adam, Entropy, 20 Epochs" ,
classification_report(y_test, predictions, output_dict = True)["1"]["f1-score"],
auroc])
evaluation.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Model | F1-1 | AUROC | |
|---|---|---|---|
| 0 | Decision Trees - Random Forest | 0.461339 | 0.768458 |
| 1 | Logistic Regression (Optimal Cutoff) | 0.527665 | 0.765244 |
| 2 | SVM-RBF (Grid Search) | 0.482247 | 0.748465 |
| 3 | Neural Network - 17x8x8x1 Adam, Entropy, 20 Ep... | 0.535834 | 0.741382 |
| 5 | Naive Bayes | 0.526342 | 0.741382 |
Naive Bayes classifier is a probabilistic machine learning model used for classification. The crux of the classifier is based on the Bayes theorem.
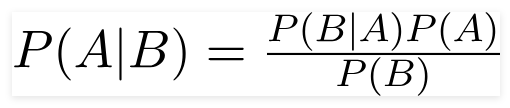
from sklearn import datasets
from sklearn import metrics
import matplotlib.pyplot as plt
import time
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
gnb = GaussianNB()#training naive bayes model
gnb.fit(X_train, y_train)GaussianNB(priors=None, var_smoothing=1e-09)
#classifying values
predicted = gnb.predict(X_train)
expected = y_train#plot roc for naive Bayes
auroc = get_roc(gnb, y_test, X_test, "Naive Bayes")Optimal Threshold: 0.9999935527715175

#accessing model performance
#print(metrics.confusion_matrix(expected, predicted))
print(classification_report(y_train,gnb.predict(X_train))) precision recall f1-score support
0 0.91 0.11 0.20 13442
1 0.25 0.96 0.39 4054
accuracy 0.31 17496
macro avg 0.58 0.54 0.29 17496
weighted avg 0.76 0.31 0.24 17496
We observe that while the recall is 0.96, the f1 is 0.39 and the overall accuracy is atrocious.
We will now try searching for the smoothing parameter to achieve a better ROC and F1 on default. After some experimentation we found that 0.01 is a good value for this parameter.
gnb = GaussianNB(var_smoothing = 0.01)
#experimenting with smoothing constant of naive bayes model on the training set.
gnb.fit(X_train, y_train)
auroc = get_roc(gnb, y_test, X_test, "Naive Bayes")
print(classification_report(y_train,gnb.predict(X_train)))Optimal Threshold: 0.038218795916133315

precision recall f1-score support
0 0.86 0.85 0.85 13442
1 0.52 0.52 0.52 4054
accuracy 0.78 17496
macro avg 0.69 0.69 0.69 17496
weighted avg 0.78 0.78 0.78 17496
Smoothing constant of 0.01 allowed us to acheieve a recall and f1 of 0.52 on the training set. Applied on the test set:
#plot roc for naive Bayes
auroc = get_roc(gnb, y_test, X_test, "Naive Bayes")
print(classification_report(y_test,gnb.predict(X_test)))Optimal Threshold: 0.038218795916133315

precision recall f1-score support
0 0.86 0.86 0.86 6762
1 0.52 0.53 0.53 1987
accuracy 0.78 8749
macro avg 0.69 0.69 0.69 8749
weighted avg 0.78 0.78 0.78 8749
evaluation.loc[5] = (["Naive Bayes" ,
classification_report(y_test, gnb.predict(X_test), output_dict = True)["1"]["f1-score"],
auroc])evaluation.sort_values(["AUROC"], ascending = False).dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Model | F1-1 | AUROC | |
|---|---|---|---|
| 0 | Decision Trees - Random Forest | 0.461339 | 0.768458 |
| 1 | Logistic Regression (Optimal Cutoff) | 0.527665 | 0.765244 |
| 3 | Neural Network 17x8x8x1 | 0.535834 | 0.761854 |
| 2 | SVM-RBF (Grid Search) | 0.482247 | 0.748465 |
| 5 | Naive Bayes | 0.526342 | 0.741382 |
raise(Exception("Stop Running"))---------------------------------------------------------------------------
Exception Traceback (most recent call last)
<ipython-input-106-c8b15946227a> in <module>
----> 1 raise(Exception("Stop Running"))
Exception: Stop Running
model = Sequential()
model.add(Dense(12, input_dim=46, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adamax', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test, "Tuning Keras Model")
print(classification_report(y_test,predictions))model = Sequential()
model.add(Dense(12, input_dim=46, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adadelta', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test, "Tuning Keras Model")
print(classification_report(y_test,predictions))model = Sequential()
model.add(Dense(12, input_dim=46, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adagrad', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test, "Tuning Keras Model")
print(classification_report(y_test,predictions))
model = Sequential()
model.add(Dense(12, input_dim=46, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test, "Tuning Keras Model")
print(classification_report(y_test,predictions))model = Sequential()
model.add(Dense(12, input_dim=46, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test, "Tuning Keras Model")
print(classification_report(y_test,predictions))model = Sequential()
model.add(Dense(12, input_dim=17, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adagrad', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train_filter, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test_filter).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test_filter, "Neural Network - adagrad (filtered features)")
print(classification_report(y_test,predictions))
evaluation.loc[6] = (["Neural Network - adagrad" ,
classification_report(y_test, predictions, output_dict = True)["1"]["recall"],
auroc])
evaluationmodel = Sequential()
model.add(Dense(12, input_dim=46, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adagrad', metrics=['accuracy'])
# fit the keras model on the dataset
model.fit(X_train, y_train, epochs=10, batch_size=10)
predictions = list(model.predict(X_test).ravel() > 0.5)
#confusion(y_test, model.predict(X_test[sig.index]), "Deep Learning Keras Model")
auroc = get_roc(model, y_test, X_test, "Neural Network - adagrad (all features)")
print(classification_report(y_test,predictions))
evaluation.loc[6] = (["Neural Network - adagrad" ,
classification_report(y_test, predictions, output_dict = True)["1"]["recall"],
auroc])
evaluation