Horovod has the ability to record the timeline of its activity, called Horovod Timeline.
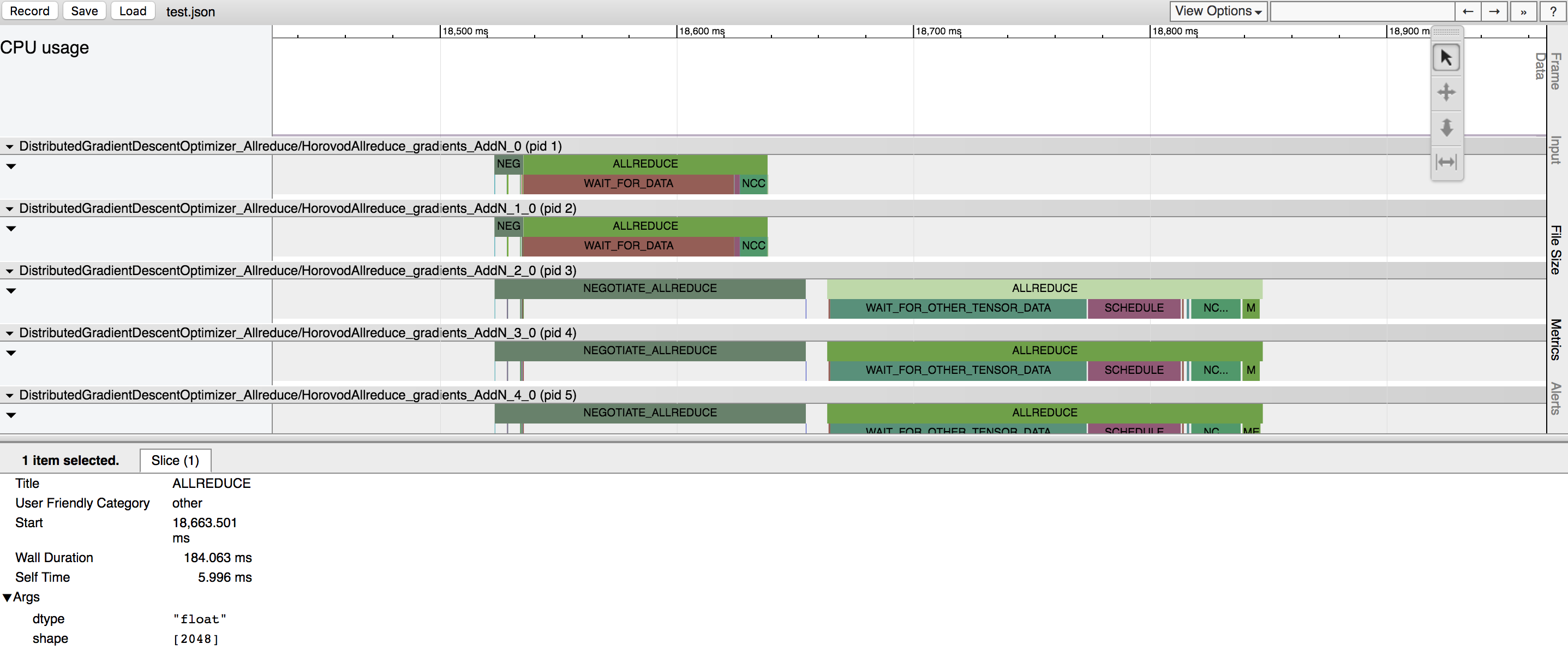
To record a Horovod Timeline, set the HOROVOD_TIMELINE environment variable to the location of the timeline
file to be created. This file is only recorded on rank 0, but it contains information about activity of all workers.
$ HOROVOD_TIMELINE=/path/to/timeline.json mpirun -np 4 -x HOROVOD_TIMELINE python train.pyYou can then open the timeline file using the chrome://tracing facility of the Chrome browser.
In the example above, you can see few tensors being reduced. There are two major phases for each tensor reduction:
- Negotiation - a phase when all workers send to rank 0 signal that they're ready to reduce the given tensor.
-
Each worker reporting readiness is represented by a tick under the NEGOTIATE_ALLREDUCE bar, so you can see which workers were early and which were late.
-
Immediately after negotiation, rank 0 sends all other workers signal to start reducing the tensor.
- Processing - a phase when the operation actually happens. It is further subdivided into multiple sub-phases:
-
WAIT_FOR_DATA indicates time taken to wait for GPU to finish computing input to the allreduce, allgather, or broadcast operations. This happens because TensorFlow tries to smartly interleave scheduling and GPU computation. This is only applicable to situations where the Horovod operation is placed on GPU.
-
WAIT_FOR_OTHER_TENSOR_DATA indicates time taken to wait for GPU to finish computing other inputs for other operations that are part of the same fusion batch.
-
QUEUE happens when reduction is done with NCCL, and the previous NCCL operation did not finish yet.
-
MEMCPY_IN_FUSION_BUFFER and MEMCPY_OUT_FUSION_BUFFER indicate time taken to copy data into and out of the fusion buffer.
-
NCCL_ALLREDUCE, MPI_ALLREDUCE, MPI_ALLGATHER, or MPI_BCAST indicate time taken to do the actual operation on GPU (or CPU) and highlights whether the operation was performed using NCCL or pure MPI.
-
In case of
HOROVOD_HIERARCHICAL_ALLREDUCE=1, NCCL_ALLREDUCE will become a sequence of NCCL_REDUCE, MEMCPY_IN_HOST_BUFFER, MPI_ALLREDUCE, MEMCPY_OUT_HOST_BUFFER, NCCL_BCAST.