{kind=link}
{kind=link}
docker build -f Dockerfile.original -t images.borgy.elementai.lan/deep3d:original .
docker build -f Dockerfile.mxnet-1.2.0 -t images.borgy.elementai.lan/deep3d:mxnet-1.2.0 .
docker build -f Dockerfile.mxnet-1.2.0-cuda9.1 -t images.borgy.elementai.lan/deep3d:mxnet-1.2.0-cuda9.1 .
nvidia-docker run -v $(pwd)/output:/work/output --rm -ti -p 8888:8888 images.borgy.elementai.lan/deep3d:original jupyter notebook --ip=0.0.0.0 --no-browser deep3d.original.ipynb
nvidia-docker run -v $(pwd)/output:/work/output --rm -ti -p 8888:8888 images.borgy.elementai.lan/deep3d:mxnet-1.2.0 jupyter notebook --ip=0.0.0.0 --no-browser --allow-root deep3d.mxnet-1.2.0.ipynb
nvidia-docker run -v $(pwd)/output:/work/output --rm -ti -p 8888:8888 images.borgy.elementai.lan/deep3d:mxnet-1.2.0-cuda9.1 jupyter notebook --ip=0.0.0.0 --no-browser --allow-root deep3d.mxnet-1.2.0.ipynb
To run this code. Please install MXNet following the official document. Deep3D requires MXNet to be built with Cuda 7.0 and Cudnn 4 or above. Please open mxnet/config.mk and set USE_CUDA and USE_CUDNN to 1. Then, append EXTRA_OPERATORS=path/to/deep3d/operators to path/to/mxnet/config.mk and recompile MXNet.
Since the debut of Avatar in 2008, 3D movies has rapidly developed into mainstream technology. Roughly 10 to 20 3D movies are produced each year and the launch of Oculus Rift and other VR head set is only going to drive up the demand.
Producing 3D movies, however, is still hard. There are two ways of doing this and in practice they are about equally popular: shooting with a special 3D camera or shooting in 2D and manually convert to 3D. But 3D cameras are expensive and unwieldy while manual conversion involves an army of "depth artists" who sit there and draw depth maps for each frame.
Wouldn't it be cool if 2D-to-3D conversion can be done automatically, if you can take a 3D selfie with an ordinary phone?
In case you are already getting sleepy, here are some cool 3D images converted from 2D ones by Deep3D. Normally you need 3D glasses or VR display to watch 3D images, but since most readers won't have these we show the 3D images as GIFs.








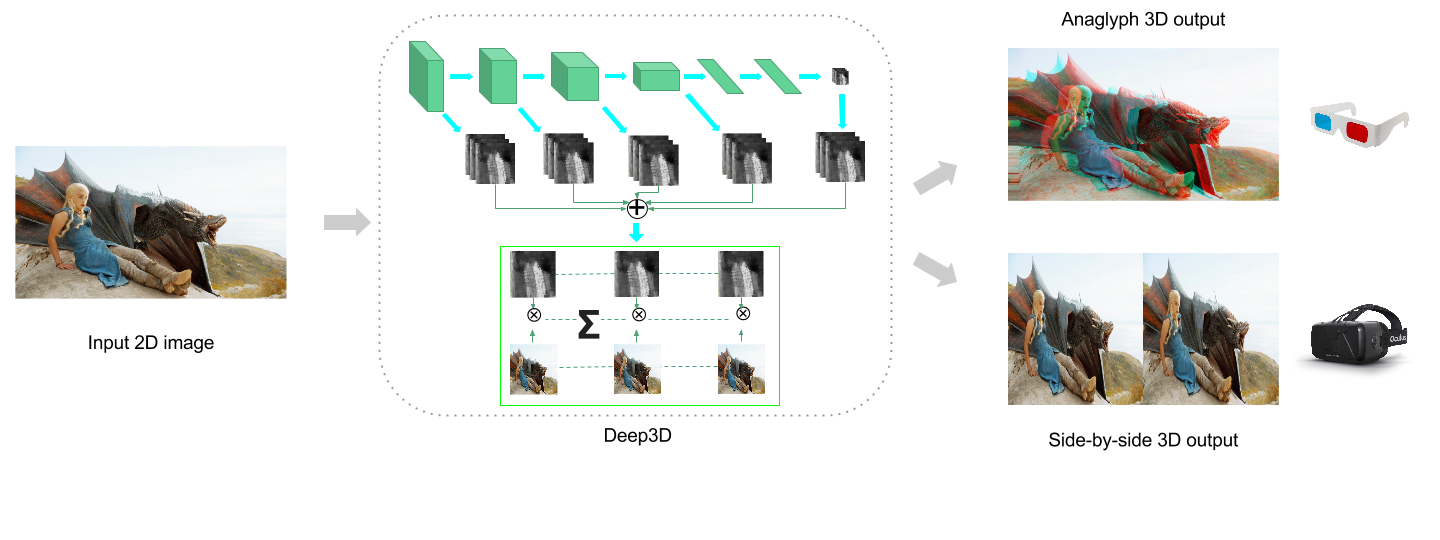
3D imagery has two views, one for the left eye and the other for the right. To convert an 2D image to 3D, you need to first estimate the distance from camera for each pixel (a.k.a depth map) and then wrap the image based on its depth map to create two views.
The difficult step is estimating the depth map. For automatic conversion, we would like to learn a model for it. There are several works on depth estimation from single 2D image with DNNs. However, they need to be trained on image-depth pairs which are hard to collect. As a result they can only use small datasets with a few hundred examples like NYU Depth and KITTI. Moreover, these datasets only has static scenes and it's hard to imagine they will generalize to photos with people in them.
In Contrast, Deep3D can be trained directly on 3D movies that have tens of millions frames in total. We do this by making the depth map an internal representation instead of the end prediction. Thus, instead of predicting an depth map and then use it to recreate the missing view with a separate algorithm, we train depth estimation and recreate end-to-end in the same neural network.
Here are some visualizations of our internal depth representation to help you understand how it works:









Following each image, there are 4-by-3 maps of depth layers, ordered from near to far. You can see that objects that are near to you appear in the first depth maps and objects that are far away appear in the last ones. This shows that the internal depth representation is learning to infer depth from 2D images without been directly trained on it.
This work is done with MXNet, a flexible and efficient deep learning package. The trained model and a prediction script is in deep3d.ipynb. We will release the code for training shortly.