


A seguir, os projetos centrais de destaque no meu perfil!
Link > https://github.com/JoSEPHDev2022/Dash_Financeiro_Power_BI
O objetivo central desse projeto foi de desenvolver minhas capacidades de extração de dados, transformação desses registros utilizando a linguagem DAX do Power BI, engenharia de atributos e criação de medidas na plataforma de dashboards, assim como também criar um dashboard com um design intuitivo e amigável, com cores e padronizações especificas para cada empresa e seu respectivo relatório.
Link > https://github.com/JoSEPHDev2022/EDA_Pirated_Movies
Este projeto tem como objetivo servir de aprimoramento em minhas capacidades de análise de dados utilizando estatística descritiva, gráficos e plots com Python, manipulação de dados com Pandas entre outras coisas. Como toda Análise Exploratória que realizo, esse projeto segue um caminho definido de etapas (esse caminho está descrito mais abaixo neste README). Por se tratar de um projeto bem detalhado e com várias etapas, ele ainda encontra-se em produção, porém deixo em destaque por se tratar do meu projeto mais recente e avançado de EDA.
3. Machine-Learning com Power BI: Utilizando o Power BI em Conjunto com Python Para Criar Visualizações
Link > https://github.com/JoSEPHDev2022/Dash_Machine_Learning
Nesse projeto, utilizei de técnicas de Machine Learning para realizar a Clusterização de Clientes de um dataset fictício. Após isso, foi criado um Dashboard pelo próprio Jupyter, Dash que foi publicado para o Power BI Service para poder ser aberto no Power BI Desktop para manipulação final.
Olá! me chamo José Luiz, um brasileiro residente do estado de São Paulo que está em busca de um constante aprimoramento profissional na área de Dados! Para uma visão mais holistica sobre mim, recomendo uma passadinha em meu LinkedIn! Mas para dar alguns bullet-points:
-
👨💻 Atualmente estou focando em aprimorar minhas habilidades com Python, focando em me especializar ainda mais em Data Analytics, principalmente com Análise Exploratória de Dados usando estatística;
-
🔭 Atualmente trabalho como professor assistente na mesma instituição em que estudei análise de dados! Resília Educação. Lá eu ensino e ajudo os alunos a aprender e crescer usando a linguagem Python para fazer projetos incríveis de análise de dados;
-
Gosto de jogar games, codar, fazer projetos paralelos como análise exploratória de dados em vários conjuntos de dados, ouvir música metal (banda favorita: Bolt Thrower 🎧 🤘) e dar muito carinho nas minhas gatinhas ❤️🐱;
-
💬 Adoro conversar com as pessoas e compartilhar histórias.
-
⚡ Curiosidade: sou formado em História e desenvolvi um projeto de pesquisa acadêmica na área, antes de vir para a área de Data Analysis!
Por aqui você encontrará uma gama de repositórios, alguns pertencentes ao meu período de estudante na Resilia Educação, onde esses projetos geralmente consistem em programação em Python e conceitos mais simples, contendo código escrito por um iniciante em Python! Por mais que esses projetos estejam desatualizados e eu já tenha ultrapassado as habilidades apresentadas neles, sempre acho legal deixá-los amostra para demonstrar minha evolução na área!
Os projetos centrais são de Análise Exploratória de Dados, algo que amo fazer em todo tipo de Dataset. Cheque a seção de "Portfólio" para entrar em contato com os mais recentes e avançados.
| Seaborn |
| Tableau |
1. Compreendendo os Dados
Nesta primeira etapa, após coletar e importar os dados, trabalho para obter uma ideia geral do Dataset e, para isso, utilizo os seguintes métodos do Pandas:
data.describe() # Descrição estatística das variáveis.
data.info() # Informações gerais sobre as variáveis, como dtypes e uso de memória.
data.isna() # Contagem do total de pontos de dados nulos.
data.shape() # As dimensões do conjunto de dados (quantas linhas e colunas).2. Preparando e Transformando os Dados
Esta etapa é muito importante, pois é onde manipulo o conjunto de dados, alterando tipos de dados, nomes de variáveis e também projetando novos recursos para o conjunto de dados, ou seja, crio novas variáveis com base nas existentes para aumentar ainda mais minhas capacidades de análise. Em outras palavras, essa etapa consiste em:
-
Eliminar variáveis inúteis ou indesejáveis;
-
Renomear as variáveis, se necessário;
-
Lidar com valores ausentes;
-
Alterar tipos de dados;
-
Lidar com duplicatas;
-
Adicionar novos recursos ao conjunto de dados (engenharia de recursos).
3. Análise Univariada
Aqui começo minha avaliação em busca de outliers e, para isso, uso principalmente os seguintes recursos:
data.hist() # Histograma para visualizar a distribuição dos dados.
data.value_counts() # Determine quais pontos de dados estão ocorrendo mais vezes na variável.
data.skew() # Determine a assimetria dos dados.
data.kurt() # Determine a Curtose dos dados.Para referência, é assim que determinamos assimetria:
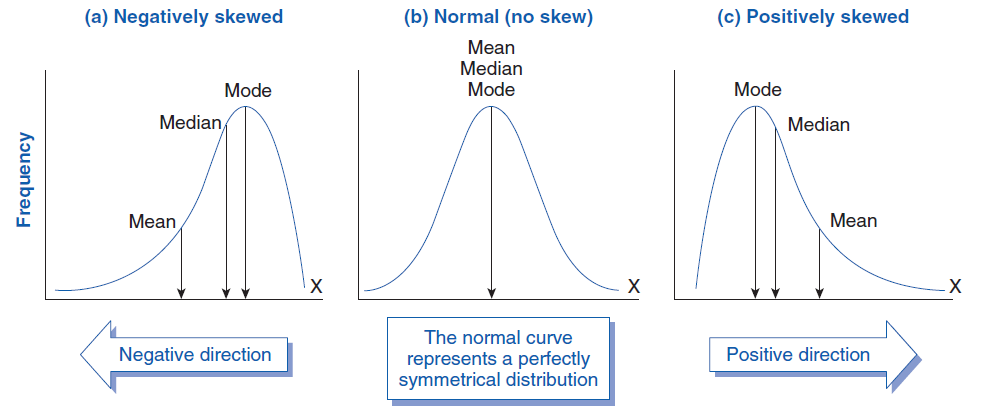
E, para a Curtose:

4. Análise multivariada
É aqui que analiso a correlação entre as diferentes variáveis do Dataset, para isso, utilizo os heatmaps, pairplots e boxplots da biblioteca seaborn.
5. Perguntas, percepções e respostas
Como etapa final, faço várias perguntas relevantes após a análise dos dados, buscando descobrir os insights mais relevantes para aquele conjunto de dados específico.
Gostou do que viu por aqui? Tem feedbakcs para me dar? Quer bater um papo sobre meus projetos e ideias? Entre em contato por: