
![]()


This is a PyTorch implementation of the training algorithm found in Denoising Diffusion Probabilistic Models.
Specifically, we implement the following training procedure:

Where
pip install:
pip install ProbabilisticDiffusion
For any additional needs, sdist and bdist can be found in the GitHub repo.
The data we use for the below examples is a set of randomly generated points points lying on a circle of radius 2 and added i.i.d gaussian noise with SD of 0.3 to x and y axes:

The Jupyter Notebook with this example can be found on GitHub here.
Below we define our model with the parameters we would like to learn. In this case we use a simple
architecture with a combination of PyTorch Linear layers with Softplus activations, as well as an embedding to take into
account the timestep,
import torch.nn as nn
import torch.nn.functional as F
class ConditionalLinear(nn.Module):
def __init__(self, num_in, num_out, n_steps):
super(ConditionalLinear, self).__init__()
self.num_out = num_out
self.lin = nn.Linear(num_in, num_out)
self.embed = nn.Embedding(n_steps, num_out)
self.embed.weight.data.uniform_()
def forward(self, x, y):
out = self.lin(x)
gamma = self.embed(y)
out = gamma.view(-1, self.num_out) * out
return out
class ConditionalModel(nn.Module):
def __init__(self, n_steps):
super(ConditionalModel, self).__init__()
self.lin1 = ConditionalLinear(2, 128, n_steps)
self.lin2 = ConditionalLinear(128, 128, n_steps)
self.lin3 = nn.Linear(128, 2)
def forward(self, x, y):
x = F.softplus(self.lin1(x, y))
x = F.softplus(self.lin2(x, y))
return self.lin3(x)We define our diffusion based model with 200 timesteps, MSE loss (although the original algorithm specifies just SSE but we found that MSE works as well), beta start and end values of 1e-5, 1e-2 respectively with a linear schedule, and use the ADAM optimizer with a learning rate of 1e-3.
from ProbabilisticDiffusion import Diffusion
import torch
n_steps=200
model = ConditionalModel(n_steps)
loss = torch.nn.MSELoss(reduction='mean') # We use MSE for the loss which adheres to the gradient step procedure defined
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # ADAM Optimizer Parameters for learning
diffusion = Diffusion(data, n_steps, 1e-5, 1e-2, 'linear', model, loss, optimizer) # Note the (1e-5, 1e-2) are Beta start and end valuesThis allows us to see the forward diffusion process and ensure that our n_steps parameter is large enough. We want to see the data morph into standard gaussian distributed points by the last time step.
import scipy.stats as stats
noised = diffusion.forward(199, s=5)
stats.probplot(noised[:,0], dist="norm", plot=plt)
plt.show()

We train with batch size of 1,000 for 10,000 epochs.
diffusion.train(1000, 10000)

We can sample new data based on the learned model via the following method:
new_x = diffusion.sample(1000, 50, s=3)
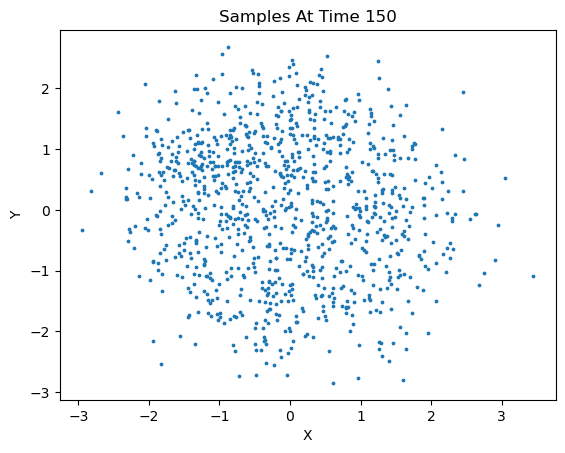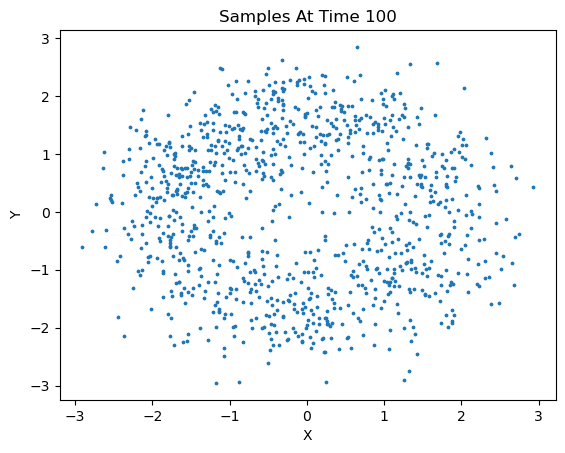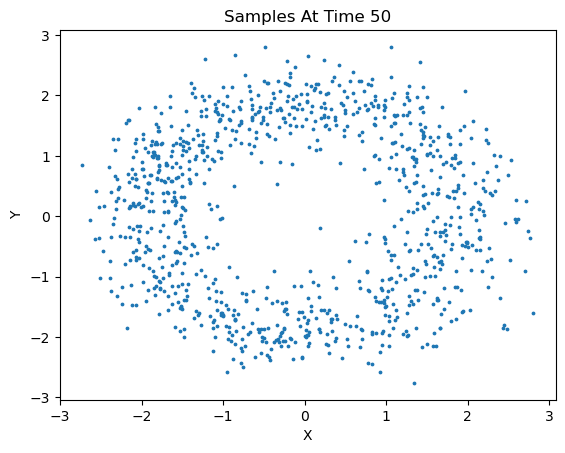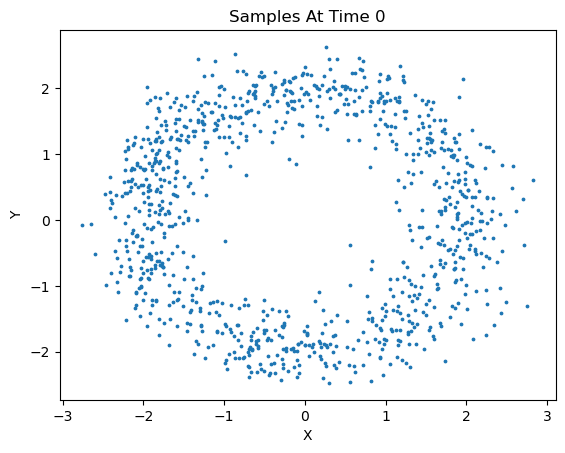
This method generated 1000 new samples and plotted at an interval of 50. In addition, we can specify which points to keep from these new samples, 'last' will only keep the last timestep of samples, 'all', will keep all timesteps, and for more granularity, one can specify a tuple of integer values corresponding to the desired timesteps to keep.