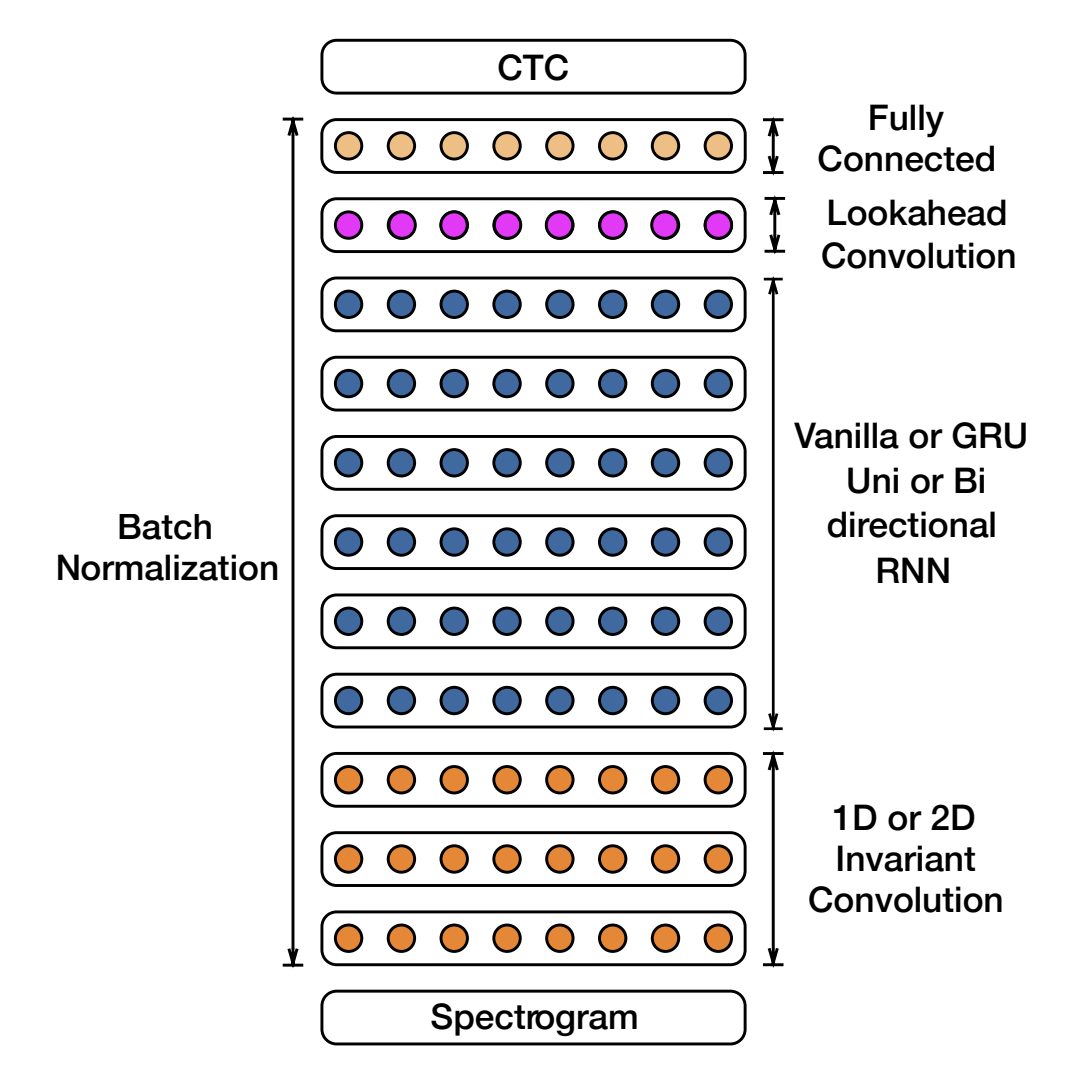
This repository contains an implementation of the paper Deep Speech 2: End-to-End Speech Recognition using Lightning AI ⚡. Deep Speech 2 was a state-of-the-art automatic speech recognition (ASR) model designed to transcribe speech into text with end-to-end training using deep learning techniques in 2015.
-
Clone the repository:
git clone --recursive https://github.com/LuluW8071/Deep-Speech-2.git cd deep-speech-2 -
Install Pytorch and required dependencies:
pip install -r requirements.txt
Ensure you have
PyTorchandLightning AIinstalled.
This implementation supports LibriSpeech. The datasets are automatically downloaded and preprocessed during training.
Important
Before training make sure you have placed comet ml api key and project name in the environment variable file .env.
To train the Deep Speech 2 model, use the following command for default training configs:
python3 train.pyCustomize the pytorch training parameters by passing arguments in train.py to suit your needs:
Refer to the provided table to change hyperparameters and train configurations.
| Args | Description | Default Value |
|---|---|---|
-g, --gpus |
Number of GPUs per node | 1 |
-g, --num_workers |
Number of CPU workers | 8 |
-db, --dist_backend |
Distributed backend to use for training | ddp_find_unused_parameters_true |
--epochs |
Number of total epochs to run | 50 |
--batch_size |
Size of the batch | 32 |
-lr, --learning_rate |
Learning rate | 1e-5 (0.00001) |
--checkpoint_path |
Checkpoint path to resume training from | None |
--precision |
Precision of the training | 16-mixed |
python3 train.py
-g 4 # Number of GPUs per node for parallel gpu training
-w 8 # Number of CPU workers for parallel data loading
--epochs 10 # Number of total epochs to run
--batch_size 64 # Size of the batch
-lr 2e-5 # Learning rate
--precision 16-mixed # Precision of the training
--checkpoint_path path_to_checkpoint.ckpt # Checkpoint path to resume training from