URL Route Management
As your application matures, you will likely encounter situations where the default assumption of mounting and accessing your application at the root path / will no longer hold. This article outlines some of the issues and complexities that you will likely encounter over time, and what solutions can be applied.
As requirements and technologies are introduced to the application, they have the possibility of making the default / path strategy no longer work. Below we outline some of the complexity factors that you may encounter, their background, and what the solutions for them could be.
- Keycloak
- Vanity URL with
/path - PR Based Pipeline
- Multi-Pod Deployment
Keycloak is a widely used Open Source Identity and Access Management solution. It is a standards compliant solution for providing Open ID Connect and OAuth IAM. One of the issues you will encounter with Keycloak client configuration is that the Valid Redirect URIs it permits is either a wildcard * for any domain, or a wildcard for a path under a specific domain such as http://domain.com/blah/*/api.
There have been discussions within the Keycloak community to add wildcard subdomain support such as http://*.domain.com. However, subdomain support is not something that can and will be supported because it goes contrary to the guidelines specified by RFC6819 - Section 5.2.3.5 and is generally considered an unsafe approach to OAuth callbacks.
As a result, the only two feasible solutions, especially when you factor in PR based pipeline support are:
- Use the insecure full
*wildcard as a valid redirect URI - Force your application to differentiate itself in the path instead of the subdomain such as
http://domain.com/pr-34/
Option one is not actually a true solution as that the wildcard effectively means that it is not checking the redirect URI validity at all. This means that you could be vulnerable to any maliciously crafted redirect callback URI. However, in certain cases, this could be considered an acceptable risk if and only if you do not care about that potential attack vector (i.e. this is on a development environment.)
Option two is therefore the only effective long-term solution to the redirect URI problem. Here, instead of differentiating the application through a unique subdomain, the differentiation point is put into the path. This would result in a valid redirect URI something along the lines of http://domain.com/*/api/auth/callback, where the wildcard allows for any subpath. This option can cleanly allow an application to use Keycloak AND the PR based pipeline, but at the cost of potentially requiring more complex networking in the cluster.
Should you have the requirement of hosting your application on a subpath of a domain which may be shared with other application tenants, you will encounter similar issues that also affects Keycloak. In addition to not being able to use the base / path anymore, you will need to ensure your application is able to listen to and mount at the correct subpath. Consideration must also be made on how the network traffic will be handled as it reaches the cluster and is passed along the internal network.
Suppose that you are required to host your application at http://domain.com/yourapp. In order for your application to continue to function at that subpath, you will need to ensure that your frontend code is expecting website resources to be found relative to the subpath. As well, your backend services must also be able to handle listening for traffic coming through the subpath. This can be achieved multiple ways. One method is to use a reverse proxy design, which will be detailed further below. The other solution can involve multi-mounting the middleware code so that it can listen and act on both the / and /yourapp paths. This method makes it so that no matter what type of traffic comes in, as long as it reaches the backend server, it can handle and respond to both subpath options.
One of the benefits of a full PR based pipeline is the ability to quickly standup proposed code changes onto a deployment environment and get useful feedback in a shorter amount of time. However, one of the requirements of a PR pipeline is the ability to stand up a distinct URL to access the new proposed change. While PR pipelines can work well in a subdomain based approach, it will inevitably conflict with Keycloak as well as any requirements for vanity URL subpaths. Ultimately a PR based pipeline will need to evolve to using path based differentiation.
A PR based pipeline using a path to differentiate will need to make sure of the following:
- Any frontend compilation is aware of the path that needs to be embedded into the static assets
- The backend servers need to be able to support listening to the appropriate subpath
- Things that may have been dealt with during runtime via environment variables will need to be migrated to the compilation step. This is because the path changes need to be embedded in the image upon build and cannot be parameterized upon pod startup.
Single-pod deployments generally do not have much route issues simply because both the frontend and backend assets are hosted by the same process. Multiple-pod deployments however do not share that convenience because the frontend and backend have different lifecycles. As well, networking considerations must be factored in because these differing deployments will likely have different services bound to them.
Openshift routes must be set up in such a way that network traffic is able to reach the right deployment. One of the common methods of handling this problem is to use a reverse proxy design, which is outlined in the next section. Another approach to exposing the services is to have a combination of different domains and paths in order to find the correct deployment. Either approach will need to consider network architecture concerns and a decent understanding of how the pods will be used in the application.
A reverse proxy is a proxy server that fetches resources from one or more servers on behalf of a client. Effectively the reverse proxy server's main function is to manage the different deployment endpoints and provide clients with one single entrypoint to access those resources.
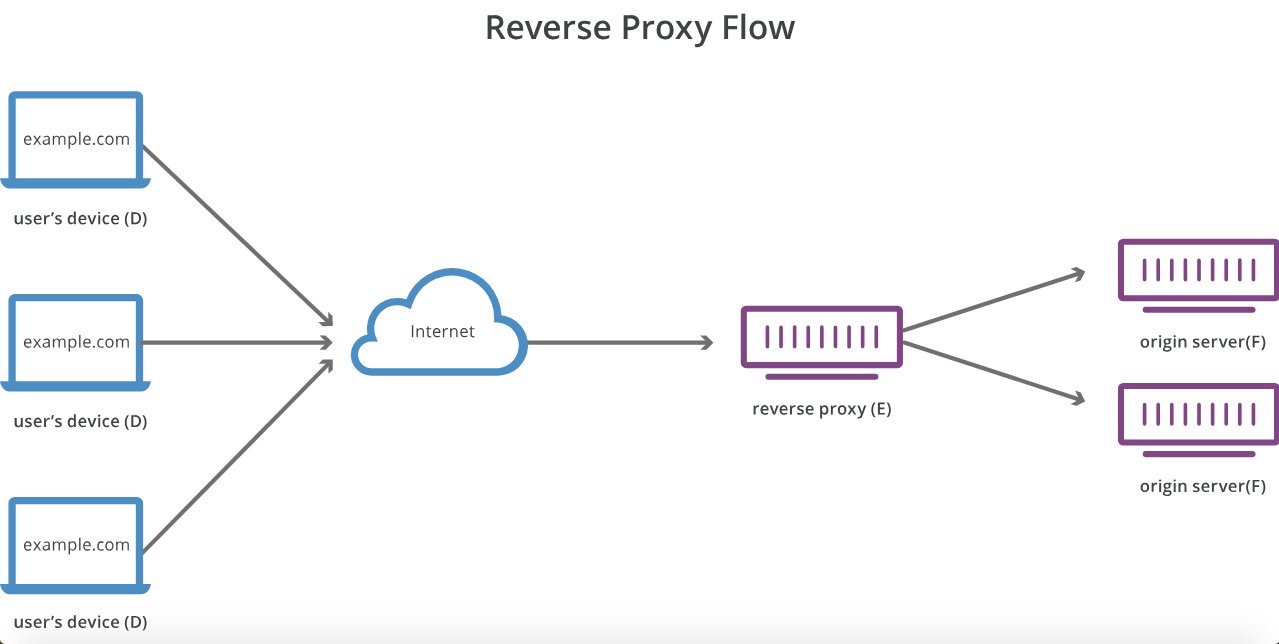
Figure 1 - Example of Reverse Proxy Flow
One of the advantages of this network pattern is that it provides the ability to easily change the urls and paths in order to fit any imposed pathing or routing constraints by redirecting or rewriting the network traffic as necessary. Some common implementations of reverse proxys include Caddy, Nginx and Apache Http Server.
As our applications are generally targeted for deployment on OpenShift, we need to ensure that our implementation is compatible with that platform. We want our network traffic from the client to all enter OpenShift through our reverse proxy service with Edge based TLS termination. Internally, we want to proxy the traffic from our reverse proxy to the backend and frontend services by leveraging the internal cluster DNS service. We want our reverse proxy service to be the only thing that is exposed to the internet at large.
While any of the above three reverse proxy solutions can work, we ultimately chose to use Caddy for the following reasons:
- Caddy configuration supports environment variable templating
- It is written in Go, which makes the pod extremely lightweight and efficient
- The configuration file of Caddy is generally much simpler to write and understand
We create a new, separate OpenShift deployment config which solely manages the reverse proxy lifecycle. The reverse proxy needs to know about the services it will proxy for and their ports, as well as the base path root that it expects all incoming traffic to have. Here we take advantage of Caddy's environment variable templating to fill in those details upon runtime. The variables can either be embedded into the OpenShift template as a named variable, or can be generated on the Jenkins pipeline as a variable parameter depending on how it is configured.
For more specific details on one of the potential implementations, take a look at the following example. You will likely also be interested in the associated OpenShift build config and deployment config and an example of how a Jenkinsfile would look like with parameterization.