Caseflow Reader
Reader is a product developed for attorneys and judges at the Board of Veteran Appeals. Attorneys and judges need to review 100's or sometimes 1000's of documents for every decision they right. Reader provides a fast and powerful interface for reviewing these documents.
Users need to have the "Reader" CSS role to access Reader. In our development mode all users have the "Reader" role, but BVASCASPER1 is the best user to test Reader with since they have several appeals to review. To open Reader go to the switch users page. Then proceed to the user's Queue. Either by going to /queue or clicking on the Queue link on the switch users page.

From the user's Queue you can navigate to Reader for any of the cases assigned to them. These cases have different numbers and different types of documents to make it easy to test different scenarios.
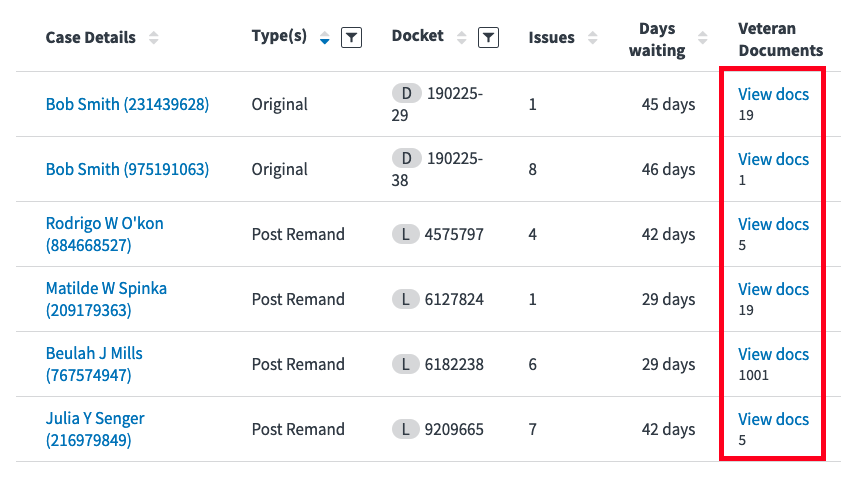
The document list is the page users will land on first. It's a directory of all the available documents. The image above is numbered to point out some of the major features:
- This accordion expands to show the user some basic information about the appeal such as the docket number, and what issues are on appeal. This feature may now be obviated by Queue's Case Details page.
- Reader provides metadata search to allow users to quickly find the document they're looking for. Users can search by date, document type, comments, issue tags, or category.
- The table allows users to both filter and sort by various columns to make case review as efficient as possible.
- Each row in the table shows metadata of the document, as well as a link to the document viewer. The link is bolded, until clicked on. Once a user has viewed a document it becomes unbolded (like a G-Mail inbox). The most recently viewed document is denoted by a small triangle.
- By clicking on the "Comments" button in this toggle users can see a list of all their comments on every document in the order of the comment's optional date field. Users can click on any of these comments to be taken to the document viewer for that document, then the viewer will automatically jump to the relevant comment.

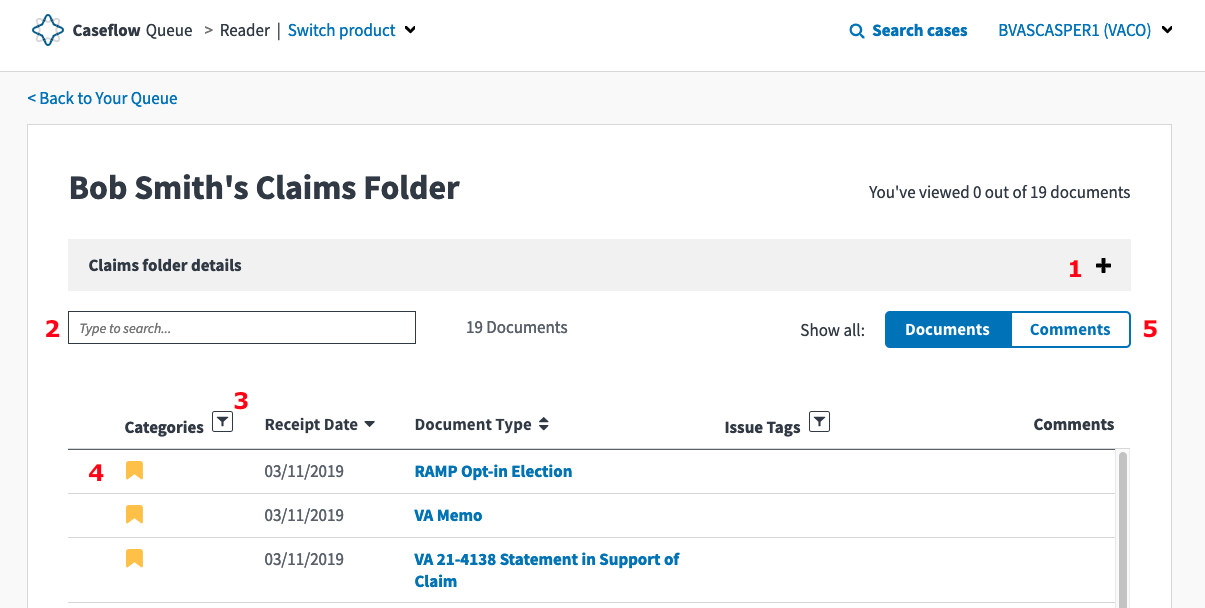
The document view is what users see when they click on the link on the document list page. It renders a PDF as well as the metadata associated with this document. The image above is numbered to point out some of the major features:
- The top toolbar is focused on manipulating the document. The + and - buttons zoom in and out respectively. The double arrow button will fit the PDF to the page, such that each page of the PDF fits exactly in the viewport. The circle arrow button will rotate the document by 90 degrees. The down arrow button will download the document to the users machine. The magnifying glass opens up a text search within the document.
- The main viewing area renders the PDF. Standard navigation works in here. Scrolling, using the up/down arrow keys, or using PageUp and PageDown to jump between pages. Comments will also appear on the rendered document. Clicking on a comment will scroll to the comment text in the comment section (#8).
- The bottom toolbar is focused on moving between documents. The Previous and Next buttons will move to the previous and next document within the list of documents. The page 1 of 4 shows the user what page they're currently on and allows them to jump to any page.
- This accordion can be expanded to show basic document information like the document type, when it was uploaded, and a user editable document description.
- All of these sections are accordions allowing users to expand or contract them to see more information on the screen.
- Categories are a way for users to specify what type of document this is. Procedural, Medical, and Other Evidence are user editable while Case Summary is automatically selected based on the document type. Selecting a category here will then show up on the document list page and allow a user to filter or search for documents using that metadata.
- Issue tags allow users to add any number of arbitrary text metadata to a document. The intended purpose for this field is to let users categorize documents based on what issue the Veteran is appeal. For example if a Veteran has an appeal for their left knee and right shoulder, some documents might apply to one, the other, or both. Users can classify each document based on what it describes and then using that metadata on the document list page to filter or search by. Note that in reality users utilize this feature to specify lots of different types of metadata, not just around what issue on appeal this document applies to.
- Users can add a comment by clicking on the "Add a comment" button, then clicking on the part of the document they want to add the comment to. They'll then be prompted with a text field for the comment text, and an optional date field that they can use to tag the comment with the relevant date an event happened. Comments appear on the document list page, and are sorted by this date. Users can utilize this feature to build a timeline of the case. What happened when, and review all their comments in that order in a single place. Users can click on the text of a comment to jump the main viewing area (#2) to the comments location in the document.
VBMS is the ultimate source of truth of Veteran documents. Each Veteran has a claims folder with documents. Reader doesn't directly integrate with VBMS, instead, Reader pulls all of the documents from another Caseflow product, eFolder Express. eFolder Express acts as Caseflow's document service, offering a number of features that make it easier to integrate with than calling VBMS directly.
eFolder Express has an endpoint /api/v2/manifests that lists all of the documents in a given Veteran's Claims Folder. This endpoint is a polling endpoint, meaning that we start by POSTing to this endpoint which prompts eFolder Express to kick off a job which downloads a list of the documents from VBMS. Then we poll the endpoint with GET requests which returns the list of documents when the job is complete. We have this structure since for large claims folders VBMS can take a very long time to respond. Note that if eFolder Express sees that the most recent call to VBMS was less than 3 hours ago, it does not make another call to VBMS and instead uses the cached value. In this way we shield the user from some of VBMS's slower endpoints. The returned manifest has a list of documents along with their associated metadata. Each document has a series_id and a version_id (unfortunately we refer to version_id as vbms_document_id in most of the code). In VBMS a document may be uploaded with multiple versions. Each version of the document gets its own version_id, but will have the same series_id. Whenever we see a new document with the same series_id as an existing document, we copy over all the metadata (comments, tags, etc.) we'd associated with that first document.
We return the list of documents to the frontend which then makes calls directly to the /api/v2/records/:id endpoint on eFolder Express to retrieve the content of a document. Note that when the backend calls the manifest endpoint, eFolder Express kicks off a separate job to start download the content of all of the documents, so that when the frontend later makes requests for content, the document contents should already be cached in S3.
There is a second store of documents known as Virtual VA (or sometimes referred to as the Legacy Content Manager). eFolder Express integrates with VVA, so when we call the manifest endpoint we get VVA as well as VBMS documents. We can also retrieve VVA documents via the record endpoint.
Unfortunately, not all of the documents in VVA are PDFs. Some are instead TIFF files. Our frontend can only render PDFs so we've set up a small Docker service which uses ImageMagick to convert TIFF files into PDFs. There are a small set of TIFFs which currently cannot be converted like this that we can therefore not render.
We aim to empower our users to review documents as quickly as possible. Load times are both frustrating for users and hurt Veterans by making VA employees less efficient at their work. So making the application quick, is a worthwhile investment. Here we discuss two of the more intricate technical decisions we've made to improve Reader performance.