Pengwei Liang, Junjun Jiang, Xianming Liu, and Jiayi Ma
Harbin Institute of Technology, Harbin 150001, China. Electronic Information School, Wuhan University, Wuhan 430072, China.
Defocus deblurring, especially when facing spatially varying blur due to scene depth, remains a challenging problem. A more comprehensive understanding of the scene can lead to spatially adaptive deblurring techniques. While recent advancements in network architectures have predominantly addressed high-frequency details, the importance of scene understanding remains paramount. A crucial aspect of this understanding is contextual information. Contextual information captures vital high-level semantic cues essential for grasping the context and meaning of the input image. Beyond just providing cues, contextual information relates to object outlines and helps identify blurred regions in the image. Recognizing and effectively capitalizing on these cues can lead to substantial improvements in image recovery. With this foundation, we propose a novel method that integrates spatial details and contextual information, offering significant advancements in defocus deblurring. Consequently, we introduce a novel hierarchical model, built upon the capabilities of the Vision Transformer (ViT). This model seamlessly encodes both spatial details and contextual information, yielding a robust solution. In particular, our approach decouples the complex deblurring task into two distinct subtasks. The first is handled by a primary feature encoder that transforms blurred images into detailed representations. The second involves a contextual encoder that produces abstract and sharp representations from the primary ones. The combined outputs from these encoders are then merged by a decoder to reproduce the sharp target image. Our evaluation across multiple defocus deblurring datasets demonstrates that the proposed method achieves compelling performance.

Given a blurred image

| Method | DPDD | RealDOF | LFDOF | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | MUSIQ | FSIM | CKDN | PSNR | SSIM | LPIPS | MUSIQ | FSIM | CKDN | PSNR | SSIM | LPIPS | MUSIQ | FSIM | CKDN | |
| Input | 23.890 | 0.725 | 0.349 | 55.353 | 0.872 | 0.492 | 22.333 | 0.633 | 0.524 | 23.642 | 0.843 | 0.413 | 25.874 | 0.777 | 0.316 | 49.669 | 0.915 | 0.524 |
| DPDNet[1] | 24.348 | 0.747 | 0.291 | 56.546 | 0.901 | 0.524 | 22.870 | 0.670 | 0.433 | 26.096 | 0.881 | 0.501 | 30.218 | 0.883 | 0.144 | 61.284 | 0.975 | 0.617 |
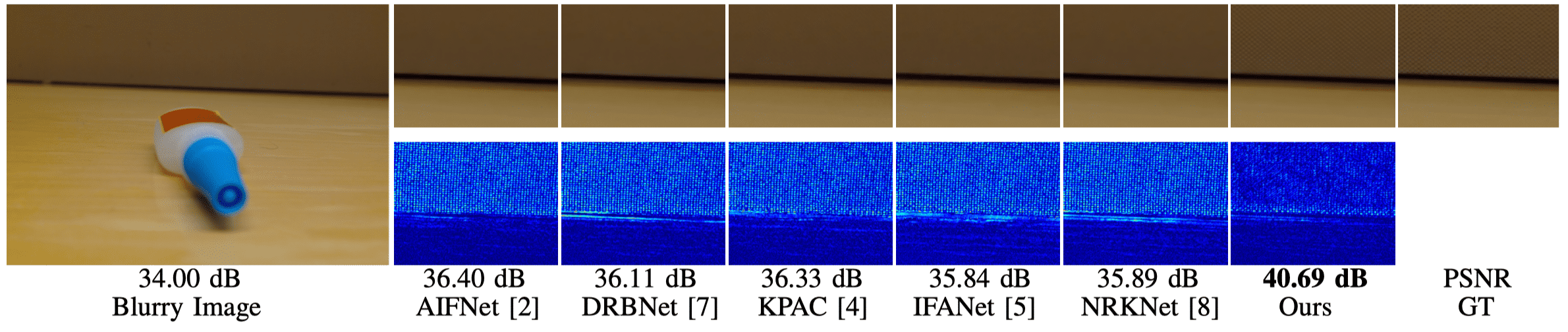
| AIFNet[2] | 24.213 | 0.742 | 0.447 | 46.764 | 0.864 | 0.502 | 23.093 | 0.680 | 0.557 | 22.502 | 0.860 | 0.461 | 29.677 | 0.884 | 0.202 | 61.481 | 0.976 | 0.624 |
| MDP[3] | 25.347 | 0.763 | 0.275 | 57.322 | 0.908 | 0.528 | 23.500 | 0.681 | 0.407 | 29.023 | 0.892 | 0.527 | 28.069 | 0.834 | 0.185 | 61.388 | 0.975 | 0.618 |
| KPAC[4] | 25.221 | 0.774 | 0.225 | 58.508 | 0.914 | 0.528 | 23.975 | 0.762 | 0.355 | 29.611 | 0.903 | 0.533 | 28.942 | 0.857 | 0.174 | 60.435 | 0.973 | 0.613 |
| IFANet[5] | 25.366 | 0.789 | 0.331 | 52.208 | 0.892 | 0.515 | 24.712 | 0.748 | 0.464 | 20.887 | 0.878 | 0.472 | 29.787 | 0.872 | 0.156 | 58.892 | 0.969 | 0.610 |
| GKMNet[6] | 25.468 | 0.789 | 0.306 | 55.845 | 0.910 | 0.531 | 24.257 | 0.729 | 0.464 | 26.938 | 0.904 | 0.508 | 29.081 | 0.867 | 0.171 | 59.038 | 0.969 | 0.605 |
| DRBNet[7] | 25.725 | 0.791 | 0.240 | 58.851 | 0.918 | 0.546 | 24.463 | 0.751 | 0.349 | 32.483 | 0.911 | 0.559 | 30.253 | 0.883 | 0.147 | 62.648 | 0.978 | 0.622 |
| Restormer[9] | 25.980 | 0.811 | 0.236 | 58.826 | 0.922 | 0.552 | 24.284 | 0.732 | 0.346 | 31.059 | 0.921 | 0.528 | 30.026 | 0.883 | 0.145 | 62.029 | 0.973 | 0.615 |
| NRKNet[8] | 26.109 | 0.810 | 0.236 | 59.118 | 0.925 | 0.546 | 25.148 | 0.768 | 0.361 | 30.237 | 0.921 | 0.561 | 30.481 | 0.884 | 0.147 | 61.738 | 0.976 | 0.620 |
| Ours | 26.114 | 0.814 | 0.201 | 60.768 | 0.934 | 0.557 | 25.141 | 0.769 | 0.295 | 34.866 | 0.932 | 0.577 | 30.508 | 0.892 | 0.144 | 62.164 | 0.977 | 0.625 |
python disttest.py -opt options/test/Unify_DDPD_Test.yaml
The full evaluation results, including DPDD, ReadDOF, and LFDOF, are available on Google Drive.
If this repo help you, please cite us:
@article{liang2024vitdeblur,
title={Decoupling Image Deblurring Into Twofold: A Hierarchical Model for Defocus Deblurring},
author={Liang, Pengwei and Jiang, Junjun and Liu, Xianming and Ma, Jiayi},
journal={IEEE Transactions on Computational Imaging},
year={2024},
pages={1207-1220},
volume={10},
publisher={IEEE}
}
[1] A. Abuolaim and M. S. Brown, “Defocus deblurring using dual-pixel data,” in Proceedings of the European Conference on Computer Vision, 2020. [code,paper]
[2] L. Ruan, B. Chen, J. Li, and M.-L. Lam, “Aifnet: All-in-focus image restoration network using a light field-based dataset,” IEEE Transactions on Computational Imaging, vol. 7, pp. 675–688, 2021.[code,paper]
[3] A. Abuolaim, M. Afifi, and M. S. Brown, “Improving single-image defocus deblurring: How dual-pixel images help through multi-task learning,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 1231–1239.[code,paper]
[4] H. Son, J. Lee, S. Cho, and S. Lee, “Single image defocus deblurring using kernel-sharing parallel atrous convolutions,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.2642–2650.[code,paper]
[5] J. Lee, H. Son, J. Rim, S. Cho, and S. Lee, “Iterative filter adaptive network for single image defocus deblurring,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2034–2042.[code,paper]
[6] Y. Quan, Z. Wu, and H. Ji, “Gaussian kernel mixture network for single image defocus deblurring,” Advances in Neural Information Processing Systems, vol. 34, pp. 20 812–20 824, 2021.[code,paper]
[7] L. Ruan, B. Chen, J. Li, and M. Lam, “Learning to deblur using light field generated and real defocus images,” in Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 304–16 313.[code,paper]
[8] Y. Quan, Z. Wu, and H. Ji, “Neumann network with recursive kernels for single image defocus deblurring,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5754–5763.[code,paper]
[9] Zamir, S. W., Arora, A., Khan, S., Hayat, M., Khan, F. S., & Yang, M. H., “Restormer: Efficient Transformer for High-Resolution Image Restoration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5728-5739.[code,paper]