剧本对影视行业的重要性不言而喻。一部好的剧本,不光是好口碑和大流量的基础,也能带来更高的商业回报。剧本分析是影视内容生产链条的第一环,其中剧本角色的情感识别是一个非常重要的任务,主要是对剧本中每句对白和动作描述中涉及到的每个角色从多个维度进行分析并识别出情感。相对于通常的新闻、评论性文本的情感分析,有其独有的业务特点和挑战。
本赛题提供一部分电影剧本作为训练集,训练集数据已由人工进行标注,参赛队伍需要对剧本场景中每句对白和动作描述中涉及到的每个角色的情感从多个维度进行分析和识别。该任务的主要难点和挑战包括: 1)剧本的行文风格和通常的新闻类语料差别较大,更加口语化; 2)剧本中角色情感不仅仅取决于当前的文本,对前文语义可能有深度依赖。
| id | content | character | emotion |
|---|---|---|---|
| 1171_0001_A_1 | 天空下着暴雨,o2正在给c1穿雨衣,他自己却只穿着单薄的军装,完全暴露在大雨之中。 | o2 | 0,0,0,0,0,0 |
| 1171_0001_A_2 | 天空下着暴雨,o2正在给c1穿雨衣,他自己却只穿着单薄的军装,完全暴露在大雨之中。 | c1 | 0,0,1,0,0,0 |
| 1171_0001_A_3 | o2一手拿着一个行李,一路小跑着把c1带到了文工团门口。 | o2 | 1,0,0,0,0,0 |
| 1171_0001_A_4 | o2一手拿着一个行李,一路小跑着把c1带到了文工团门口。 | c1 | 0,0,0,0,0,0 |
字段说明:
| 字段名称 | 类型 | 描述 | 说明 |
|---|---|---|---|
| id | String | 数据ID | 猜测是剧本_场景_id |
| content | String | 文本内容 | 剧本对白或动作描写 |
| character | String | 角色名 | 文本中提到的角色 |
| emotion | String | 情感识别结果(按顺序) | 爱情感值,乐情感值,惊情感值,怒情感值,恐情感值,哀情感值 |
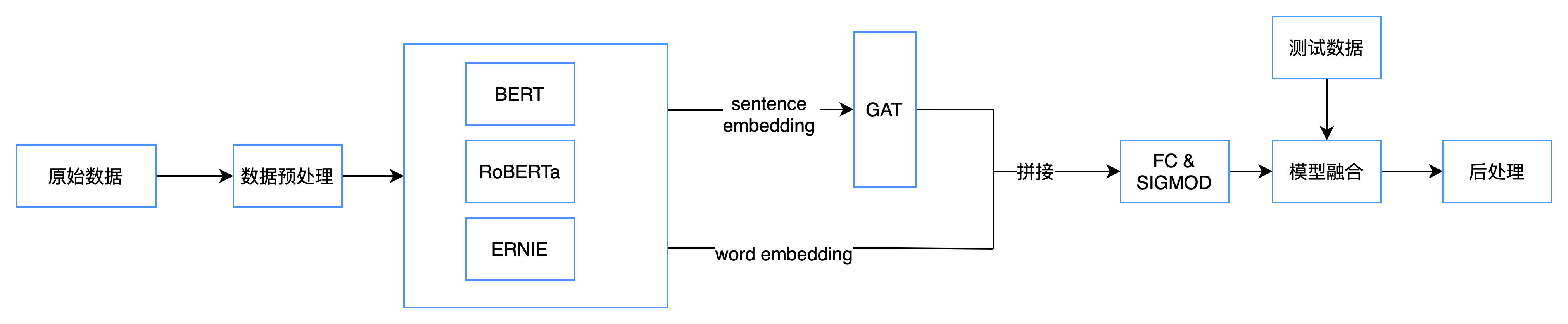
具体的:
- 取连续batch_size个句子作为一个batch
- 经过Bert得到句子表示,[batch_size, embedding_size]
- 一个batch构建一个图,经过GAT仍然返回句子表示, [batch_size, embedding_size]
- 最后接线性层,用回归算loss
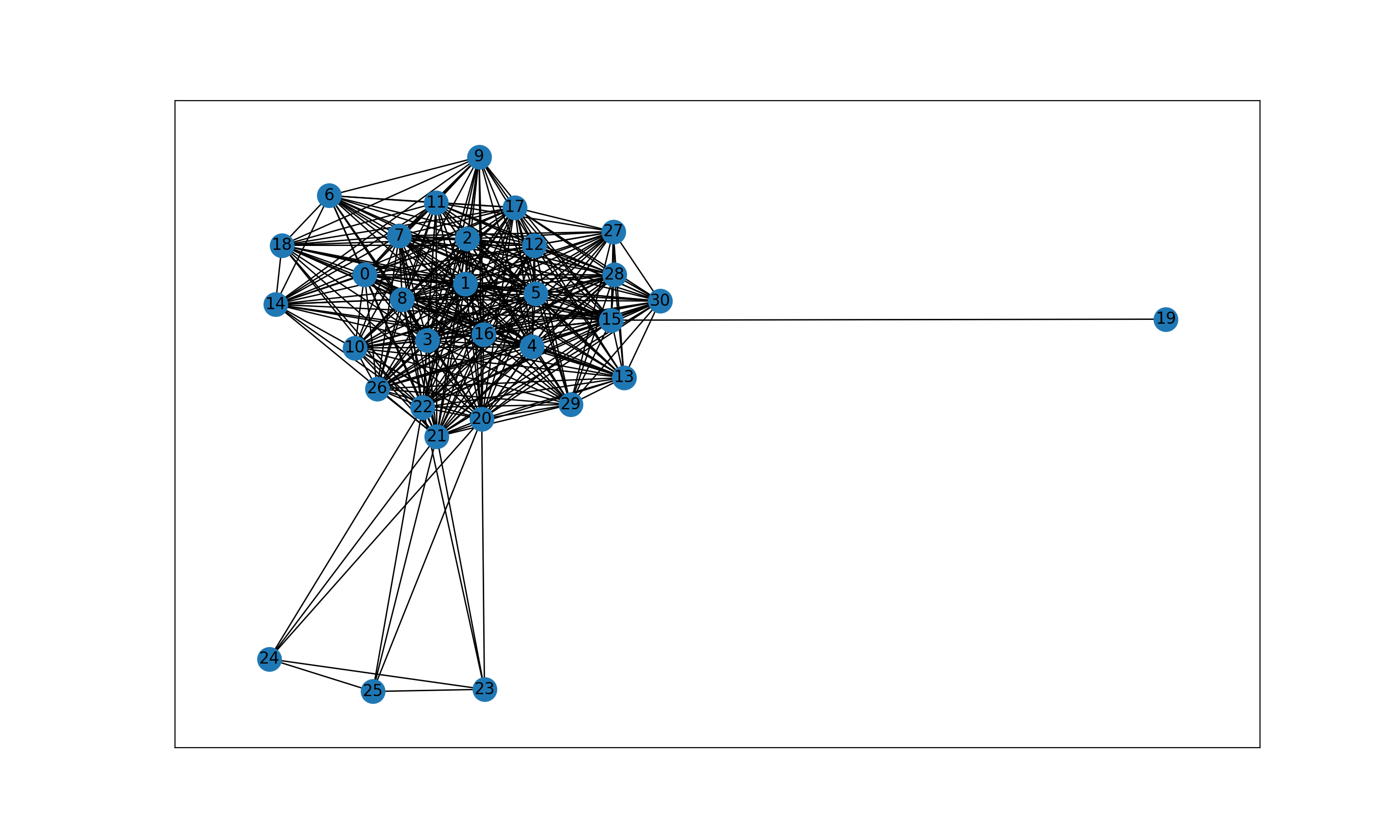
例如:前batch_size=32个句子构建的GAT图
尝试过用分类做,效果没有回归好
采用回归损失函数MSE,MSE(Mean Squred Error)叫做均方误差
此外,评测标准,也是均方根误差(RMSE)

- train.py: 主循环,训练过程
- model.py: 构建BERT+GAT模型
- predict.py: 验证和预测
- rmseloss.py: 均方误差损失函数
- gat.py : GAT模型
- fgm.py: FGSM攻击
- got_role.py: 得到文件中的所有角色
- load_data.py: 数据预处理
- roledataset.py: 自定义数据集类型
- utils.py: 工具函数
- config.py: 配置文件
utils下:
- cleardata.py: 整理数据
- dynamic_batch.py: 动态设置batch_size
- improve_result.py: 将预测结果改进, 将原本没有角色名的句子置0
- ensemble_result.py: 把多个结果加权求和
- role_file.py: 得到词汇表中的没有的角色
- visual_data.py: 分析原始数据
data下:
- train_dataset_v2.tsv: 原始训练集
- test_dataset.tsv: 原始测试集
- train.csv: 整理后的训练集
- test.csv: 整理后的测试集
- submit_example.tsv: 提交样例
logs下: 训练过程中的打印信息
runs下: tensorboard记录的loss信息
results下: 预测结果
1. 开始训练
python train.py >> logs/train.log 2>&1
2. 修正结果
python improve_result.py
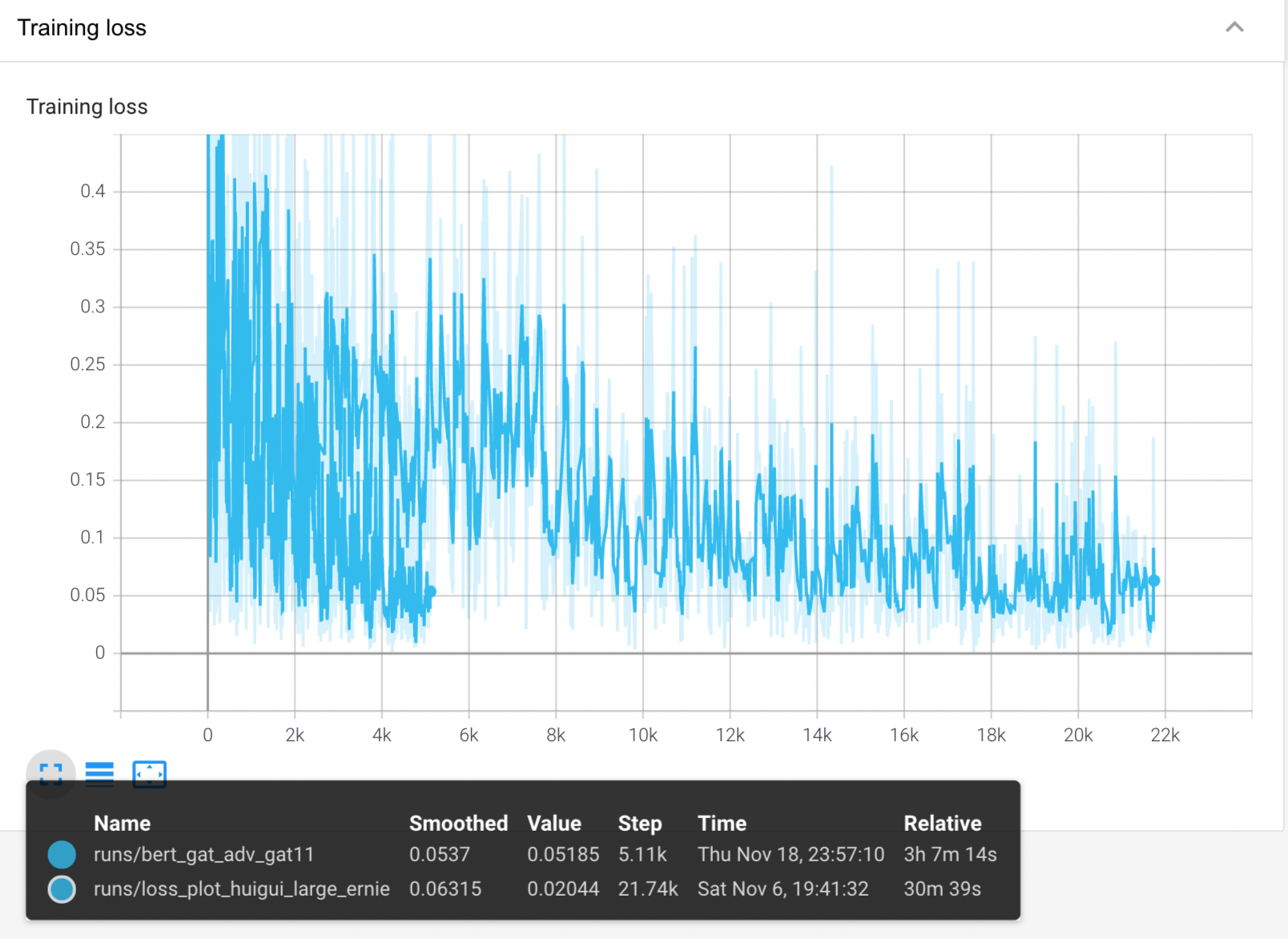
一些loss图:
- 长线是ernie, 短线是bert_gat
- bert_gat虽然step更少,但是更慢,因为它的batch_size更大,epoch_num更大
- 对比下来,ernie更快更好呢......
一些日志:见logs文件夹
预训练模型: hfl_chinese_roberta_wwm_ext(修改了vocab.txt)
链接: https://pan.baidu.com/s/1xJdL71RvLb-G4bYUuwmBpw 提取码: qq4s
checkpoint: 训练10轮后的模型
链接: https://pan.baidu.com/s/1frhD-ZzwNn4mGJcduL1i8Q 提取码: swag
32000+训练集,batch_size=64, epoch=10, 20000+测试集,batch_size=1, epoch=11 单张2080Ti 共3个小时
| 模型 | 得分 |
|---|---|
| ensemble(['./results/bert_gat_adv_improve.tsv', './results/bert_gat_adv_gat11_improve.tsv', './results/bert_gat_normal_improve.tsv'], [1/3, 1/3, 1/3]) | 0.69311495076 |
| ['./results/bert_gat_adv_improve.tsv', './results/bert_gat_adv_gat11_improve.tsv', './results/bert_gat_normal_improve.tsv'], [0.25,0.5,0.25] | 0.69292791520 |
| bert+gat,gat采用3层卷积,gat的dropout调小 | 0.69019270470 |
| 在epoch_num=5的基础上,固定bert,再训练3轮 | 0.69274829981 |
| 默认参数,epoch_num=5 | 0.69079147481 |
| ernie修正版 emo < 0.2 | 0.69204910612 |
| ernie修正版 emo < 0.5 | 0.68790208608 |
| roberta_large | 0.68978064345 |
| 未加场景,角色*2,epoch_num=5,未丢, ernie1.0 | 0.69554328794 |
| epoch_num=5, output*3, warmup_proportion=0.0, 减少50% | 0.68196819294 |
| outputs*3, 减少50%的全0 | 0.69005280956 |
| 随机扔掉30%的全0数据 | 0.69222025156 |
| 增大batch_size=32, outputs*4 | 0.68920540598 |
| 改成回归 | 0.69466536245 |
| 测试能否交小数 | 0.66664726448 |
| 全0?? | 0.66668028392 |
- 纯Bert就很不错,改进结构不如换预训练模型
- 损失函数很重要,比如此次比赛任务回归要好于分类
- 输入数据在训练前测试好,训练爆出bad case再清洗非常浪费时间
- 数据增强、伪标签、调参和模型融合是最有效的提升手段,自己想当然的idea往往瞎择腾