A C++11 High Performance Serialization Library.

HPS is a high performance header-only C++11 library for data serialization. It can encode structured data or objects into a flat and compressed format efficiently, so that we can pass them over the network or write them to the file system faster, or store them more compactly in the memory.
It has the state of the art performance and beats all the well-known serialization libraries. For example, compared to Boost Serialization, HPS is up to 150% faster and uses up to 40% less bytes for several common data structures. Check the benchmarks below for details.
In addition, it requires the least amount of human efforts to use. There is no need for making a separate schema file or using special data structures, HPS works with STL containers and user-defined types directly. This design makes the binding of data and serialization methods more cohesive and can often give a much cleaner design, especially when there is composition or inheritance between classes.
HPS is being actively used in a quantum chemistry package (developed by the Umrigar Group at Cornell University LASSP Lab) and has successfully and efficiently serialized/parsed petabytes of scientific data and reduced petabytes of network traffic due to the usage of a compact encoding scheme in HPS.
@article{li2018hps,
title={HPS: A C++ 11 High Performance Serialization Library},
author={Li, Junhao},
journal={arXiv preprint arXiv:1811.04556},
year={2018}
}
Not needed!
HPS is a header-only library.
Simply include the hps.h file, which includes all the other headers.
The performance of HPS compared to other well-known C++ serializers for some most common data structures are as follows: (less is better)
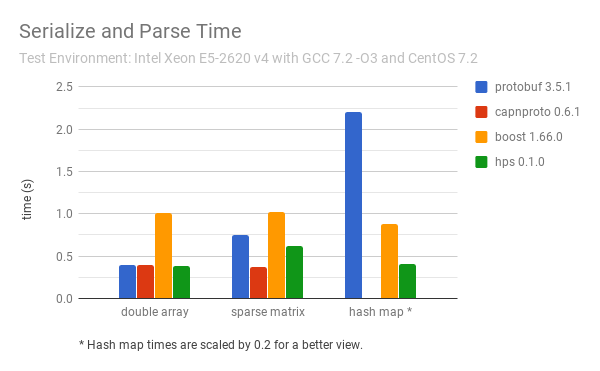
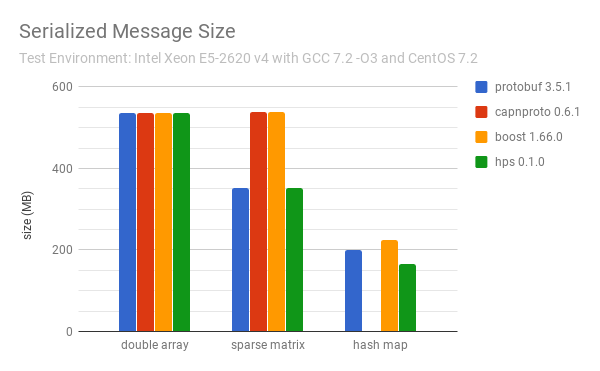
The test codes are in the benchmark directory. You can follow the continuous integration script in ci.sh to install the libraries and reproduce these results.
The sparse matrix is stored as a list of rows, each of which contains a list of 64-bit integers for the column indices and a list of doubles for the values.
The hash map is a map from strings to doubles.
Both HPS and Boost can serialize std::unordered_map directly, ProtoBuf uses its own Map type and CapnProto does not support hash map or similar types.
In addition to the traditional benchmarks for computational cost, we also provide the human efforts cost in terms of source lines of code for these test cases: (less is better)
| SLOC | double array | sparse matrix | hash map | fixed cost |
|---|---|---|---|---|
| protobuf | 12 | 23 | 12 | 17 |
| capnproto | 15 | 25 | - | 21 |
| boost | 13 | 20 | 13 | 13 |
| hps | 7 | 16 | 7 | 2 |
Note: fixed cost includes the estimated amount of lines of commands needed for an experienced user to install the library, set the environment variables, extra lines of code needed in the Makefile, and various includes, etc.
HPS is super easy to use. For primitive types and most STL containers, serialization requires only one line of code.
#include <cassert>
#include <iostream>
#include "../src/hps.h"
int main() {
std::vector<int> data({22, 333, -4444});
std::string serialized = hps::to_string(data);
auto parsed = hps::from_string<std::vector<int>>(serialized);
assert(parsed == data);
std::cout << "size (B): " << serialized.size() << std::endl;
// size (B): 6
return 0;
}
// Compile with C++11 or above.There are also the to_stream and from_stream functions for writing the data to or reading it from file streams.
For example
std::ofstream out_file("data.log", std::ofstream::binary);
hps::to_stream(data, out_file);
std::ifstream in_file("data.log", std::ifstream::binary);
auto parsed = hps::from_stream<std::vector<int>>(in_file);The bottom of this document contains all the APIs that HPS provides.
We can also extend HPS to support custom types.
HPS internally uses static polymorphism on the class Serializer<DataType, BufferType> to support different types.
Serializer<DataType, BufferType> will call the serialize and parse methods of the corresponding type by default.
All we need to do is either provide the serialize and parse methods for the new type or specialize the Serializer class, and HPS will support it, together with any combination of this type with STL containers and other specialized types.
The following example shows the serialization of a custom quantum system object by providing its serialize and parse methods.
#include <cassert>
#include <iostream>
#include "../src/hps.h"
class QuantumState {
public:
unsigned n_elecs;
std::unordered_set<unsigned> orbs_from;
std::unordered_set<unsigned> orbs_to;
template <class B>
void serialize(B& buf) const {
buf << n_elecs << orbs_from << orbs_to;
}
template <class B>
void parse(B& buf) {
buf >> n_elecs >> orbs_from >> orbs_to;
}
};
int main() {
QuantumState qs;
qs.n_elecs = 33;
qs.orbs_from.insert({11, 22});
qs.orbs_to.insert({44, 66});
std::string serialized = hps::to_string(qs);
std::cout << "size (B): " << serialized.size() << std::endl;
// size (B): 7
return 0;
}
// Compile with C++11 or above.For examples on extending HPS by specializing the Serializer class, you can check our source code for primitive types and STL containers, such as float_serializer.h, where we specialize the Serializer for all the floating point numbers (using SFINAE).
The encoding scheme of HPS is very similar to Google's protobuf. Google provides an extremely detailed exlanation on that.
The major difference between protobuf's encoding scheme and HPS' is that HPS does not store field numbers or wire types. This gives HPS a significant advantage in both the speed and the size of the serialized messages over protobuf, especially when there are many fields and nested structures.
// Serialize data t to an STL ostream.
void to_stream(const T& t, std::ostream& stream);// Parse from an STL istream and save to the data t passed in.
// Recommended for repeated use inside a loop.
void from_stream(T& t, std::istream& stream);// Parse from an STL istream and return the data.
T from_stream<T>(std::istream& stream);// Serialize data t to the STL string passed in.
// Recommended for repeated use inside a loop.
void to_string(const T& t, std::string& str);// Serialize data t to an STL string and return it.
std::string to_string(const T& t);// Parse from an STL string and save to the data t passed in.
// Recommended for repeated use inside a loop.
void from_string(T& t, const std::string& str);// Parse from an STL string and return the data.
T from_string<T>(const std::string& str);// Parse from a char array and save to the data t passed in.
// Recommended for repeated use inside a loop.
void from_char_array(T& t, const char* arr);// Parse from a char array and return the data.
T from_char_array<T>(const char* arr);HPS supports the following types and any combinations of them out of the box:
- All primitive numeric types, a.k.a.
std::is_arithmetic<T>, e.g.int, double, bool, char, uint8_t, size_t, ... - STL containers
string, array, deque, list, map, unordered_map, set, unordered_set, pair, vector, unique_ptr.
Heterogeneous data here refers to messages that contain data structures that occur repeatedly but have some fields missing irregularly.
There is no panacea for achieving the best performance for this type of data in all cases.
Protobuf uses an additional integer to indicate the existence of each field, which is best suitable for cases where there are lots of missing fields.
Another possible encoding scheme is bit representation, i.e., use a bit vector to indicate the existence of the fields.
This is best suitable for cases where fields are missing less often.
Note that there is no need to deal with bit operations manually.
An STL vector<bool> will use a compact format automatically.
And for cases where most of the fields are present, the reverse of protobuf's scheme will be the best choice, i.e., use a vector to store the indices of the missing fields.