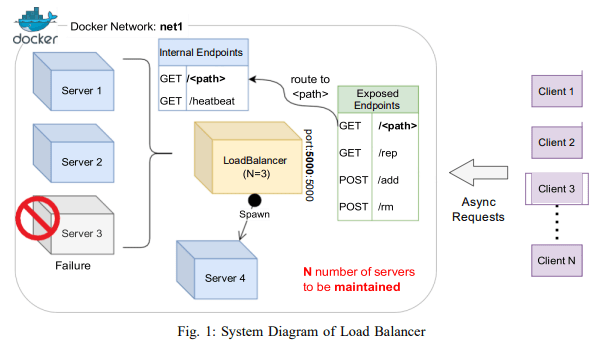
This project implements a customizable load balancer that routes requests coming from several clients asynchronously among several servers so that the load is nearly evenly distributed among them.
The load balancer is designed using a consistent hashing mechanism. This design choice was made to ensure that the load balancer can handle a large number of requests and distribute them evenly across the servers. The consistent hashing mechanism also allows the load balancer to handle changes in the number of servers without causing a significant disruption in the distribution of requests.
- The following assumptions were made during the development of this load balancer:
- The servers are capable of handling the load distributed to them by the load balancer.
- The number of servers can change dynamically, and the load balancer can handle these changes.
- The hash function used for consistent hashing provides a good distribution of requests across the servers.
-
Clone the repository on your local machine:
git clone https://github.com/mikemwai/balancer.git
-
Navigate to the project directory and create a virtual environment on your local machine through the command line:
py -m venv myenv
-
Activate your virtual environment:
-
On Windows
myenv\Scripts\activate
-
On Mac
source myenv/bin/activate
-
-
Install the required packages:
pip install -r requirements.txt
-
Navigate to the server readme to run the server and the load balancer readme to run the load balancer.
The load balancer was tested using a series of tests that simulate a variety of scenarios, including a large number of requests, changes in the number of servers, and server failures. The tests were designed to measure the performance of the load balancer and ensure that it can handle these scenarios effectively.
The performance of the load balancer was analyzed by measuring the total time taken to handle a large number of requests and the average load on the servers. The results of this analysis showed that the load balancer is able to distribute the load evenly across the servers and handle a large number of requests efficiently.
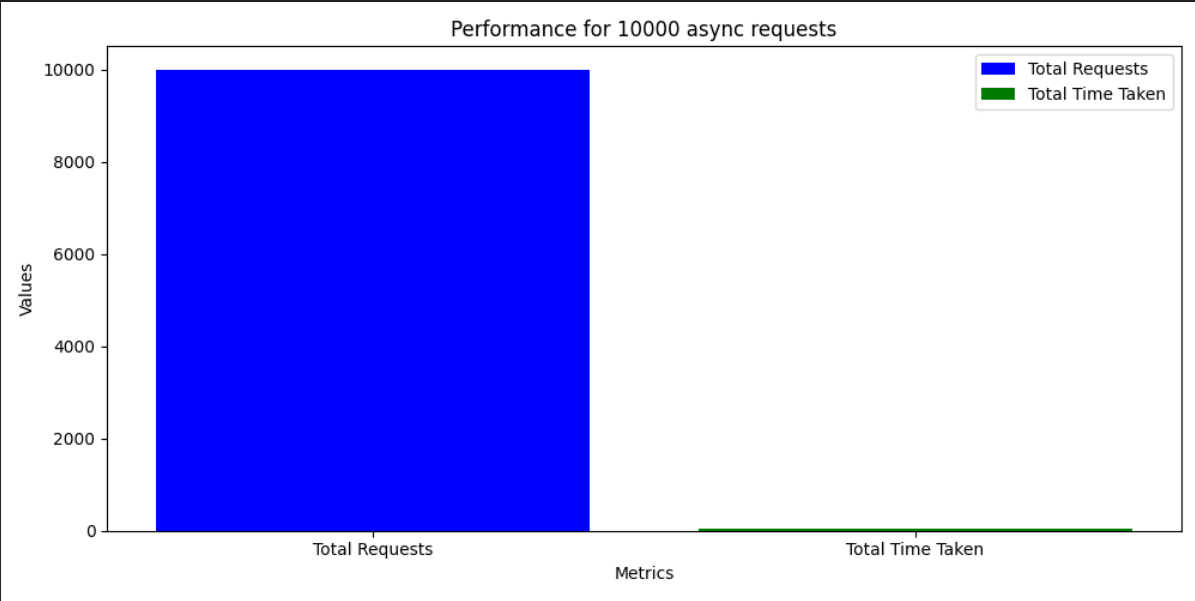
Launch 10000 async requests on N = 3 server containers and report the request count handled by each server instance in a bar chart. Explain your observations in the graph and your view on the performance.
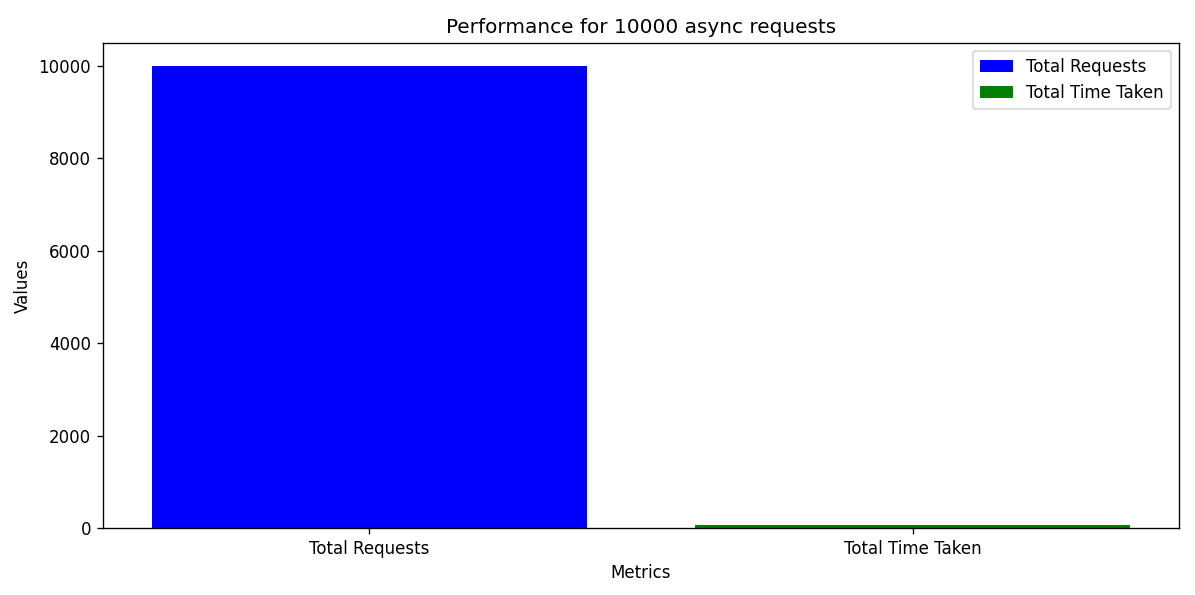

The load balancer handled 10,000 asynchronous requests in approximately 69.13 seconds. This indicates that the load balancer is capable of handling a high volume of requests in a relatively short amount of time. The average time taken per request is approximately 0.006913 seconds/request, indicating that the load balancer is able to handle each request quickly.
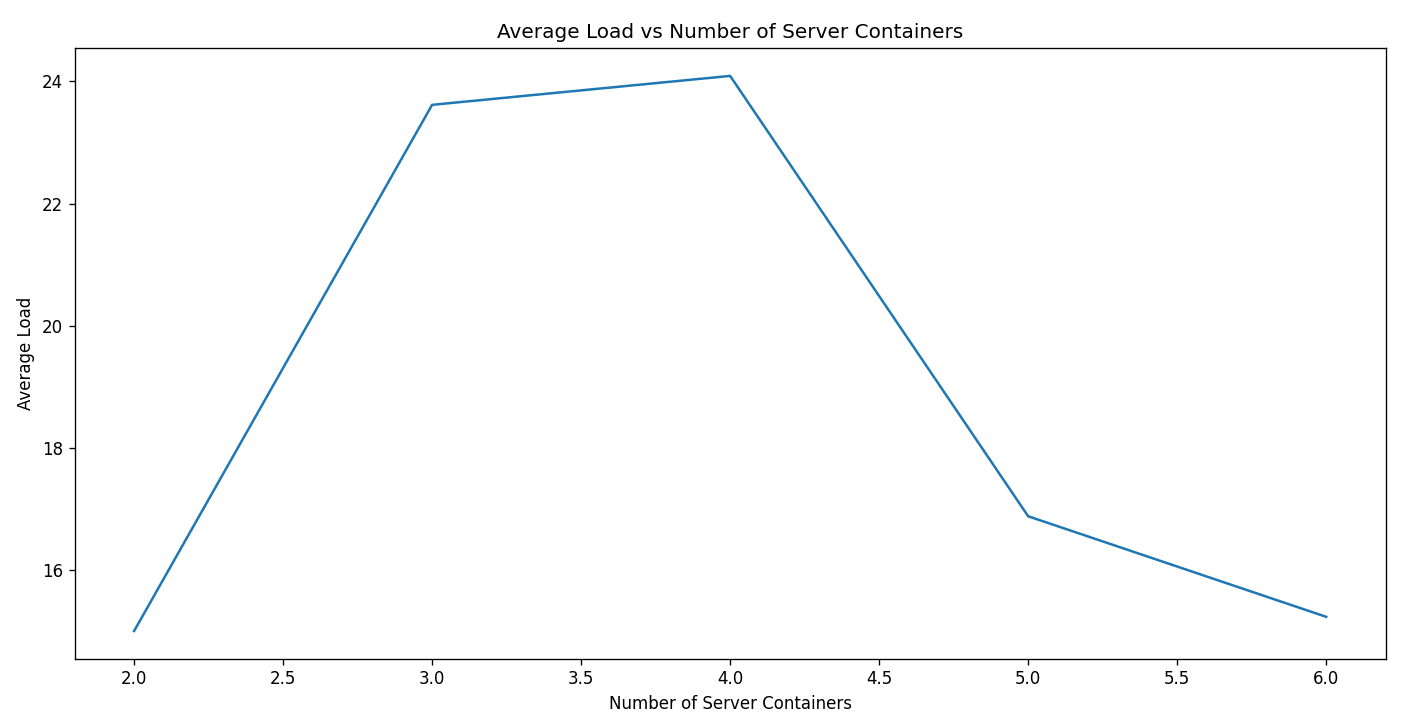
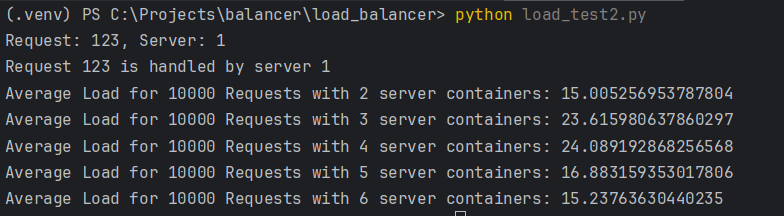
Next, increment N from 2 to 6 and launch 10000 requests on each such increment. Report the average load of the servers at each run in a line chart. Explain your observations in the graph and your view on the scalability of the load balancer implementation.
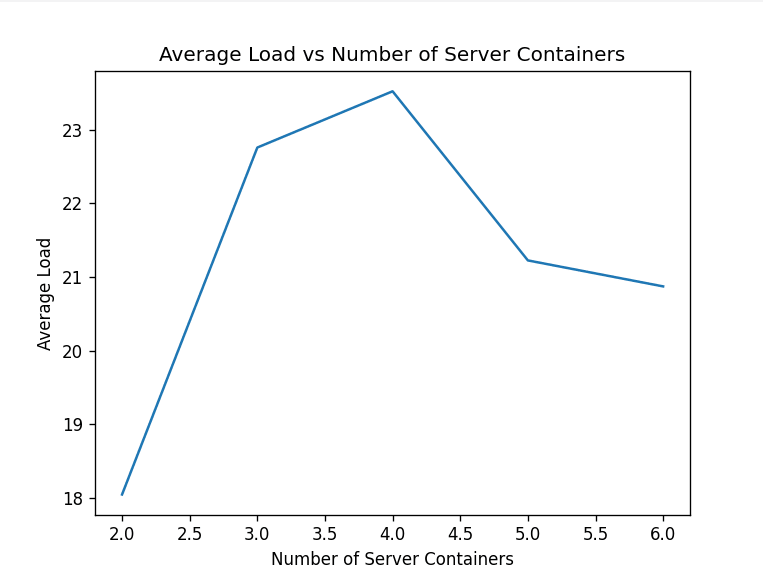
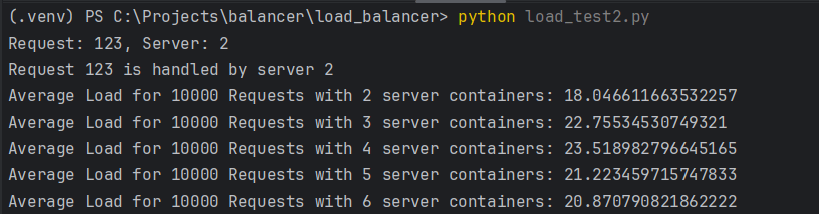
Based on the observations above, the average load time per request initially increases as the number of server containers increases from 2 to 4, then decreases as the number of server containers increases from 4 to 6. This could be due to the overhead of managing more server containers initially outweighing the benefits of having more servers to distribute the load. As the number of server containers continues to increase, the benefits of having more servers to distribute the load start to outweigh the overhead, resulting in a decrease in the average load time per request.
Test all endpoints of the load balancer and show that in case of server failure, the load balancer spawns a new instance quickly to handle the load.
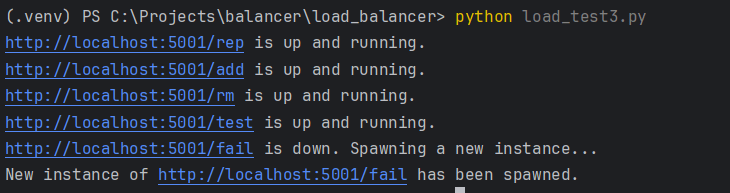
Based on the observations above, the load balancer is functioning as expected with all endpoints up and running. In case of a server failure, it quickly spawns a new instance through the new endpoint /fail to handle the load, demonstrating its resilience and reliability.
Finally, modify the hash functions H(i), Φ(i, j) and report the observations from (A-1) and (A-2).
i) A-1:

ii) A-2:
i) A-1:
Based on the observations, the total time taken to handle 10,000 requests decreased to 48.1678 seconds which is lower than the time taken in the initial test. This indicates that the modifications to the hash functions improved the efficiency of the load balancer in handling a high volume of requests.
ii) A-2:
Based on the observations, the average load time per request for different numbers of server containers also decreased compared to the initial test. This suggests that the modifications to the hash functions improved the distribution of requests across the servers, resulting in a lower average load time per request.
The project includes a centralized logging configuration and modularized request handling functions. The logging_config.py file sets up a comprehensive logging system that logs events to both the console and a file, providing better traceability and debugging capabilities. The async_requests.py script uses request_helper.py for making asynchronous HTTP requests.
-
If you'd like to contribute to this project:
- Please fork the repository.
- Create a new branch for your changes.
- Submit a pull request.
Contributions, bug reports, and feature requests are welcome!
If you have any issues with the project, feel free to open up an issue.
This project is licensed under the MIT License