generated from rhodyprog4ds/syllabus_template
-
Notifications
You must be signed in to change notification settings - Fork 1
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
f7aa704
commit 4d09a0c
Showing
7 changed files
with
372 additions
and
2 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,106 @@ | ||
| # Assignment 7 | ||
|
|
||
| [accept the assigment (link tbd)]() | ||
|
|
||
| __Due: TBA__ | ||
|
|
||
| Eligible skills: (links to checklists) | ||
|
|
||
|
|
||
| - **first chance** classification [1](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#classification-level1) and [2](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#classification-level2) | ||
| - evaluate [1](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#evaluate-level1) and [2](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#evaluate-level2) | ||
| - summarize [1](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#summarize-level1) and [2](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#summarize-level2) | ||
| - visualize [1](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#visualize-level1) and [2](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#visualize-level2) | ||
| - python [1](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#python-level1) and [2](https://rhodyprog4ds.github.io/BrownFall22/syllabus/achievements.html#python-level2) | ||
|
|
||
| ## Related notes | ||
|
|
||
| - [](../notes/2023-03-07) | ||
| - [](../notes/2023-03-09) | ||
|
|
||
|
|
||
| ## Dataset and EDA | ||
|
|
||
|
|
||
| Choose a datasets that is well suited for classification and that has all numerical features. | ||
| If you want to use a dataset with nonnumerical features you will have to convert | ||
| the categorical features to one hot encoding. | ||
|
|
||
| ```{hint} | ||
| Use the UCI ML repository | ||
| ``` | ||
|
|
||
| 1. Include a basic description of the data(what the features are) | ||
| 1. Describe the classification task in your own worlds | ||
| 1. Use EDA to determine if you expect the classification to get a high accuracy or not. What types of mistakes do you think will happen most? | ||
| 1. Explain why or why not Gaussian Naive Bayes and Decision Trees are a reasonable model to try for this data. | ||
| 1. Hypothesize which will do better and why you think that. | ||
|
|
||
|
|
||
| ## Basic Classification | ||
|
|
||
| 1. Fit your chosen classifier with the default parameters on 50% of the data | ||
| 1. Test it on 50% held out data and generate a classification report | ||
| 1. Inspect the model to answer the questions appropriate to your model. | ||
|
|
||
| - Does this model make sense? | ||
| - (DT) Are there any leaves that are very small? | ||
| - (DT) Is this an interpretable number of levels? | ||
| - (GNB) do the parameters fit the data well? | ||
| - (GNB) do the paramters generate similar synthetic data | ||
| 1. Repeat the split, train, and test steps 5 times, save the scores into a dataframe. Compute the mean and std of the scores. | ||
|
|
||
| - Is the performance consistent enough you trust it? | ||
| 1. Interpret the model and its performance in terms of the application. Example questions to consider in your response include | ||
|
|
||
| - do you think this model is good enough to use for real? | ||
| - is this a model you would trust? | ||
| - do you think that a more complex model should be used? | ||
| - do you think that maybe this task cannot be done with machine learning? | ||
|
|
||
|
|
||
| ## Exploring Problem Setups | ||
|
|
||
| ```{important} | ||
| Understanding the impact of test/train size is a part of classifcation and helps with evaluation. This exercise is *also* a chance at python level 2. | ||
| ``` | ||
|
|
||
| ````{margin} | ||
| ```{tip} | ||
| The summary statistics and visualization we used before are useful for helping to | ||
| investigate the performance of our model. We can try fitting a model with different settings | ||
| to create a new "dataset" for our experiments. | ||
| The same skills apply. | ||
| ``` | ||
| ```{hint} | ||
| The most important thing about the max depth here is that it's the same across all of the models. If you get an error, try making it smaller. | ||
| ``` | ||
| ```` | ||
| Do an experiment to compare test set size vs performance: | ||
| 1. Train a model (if decision tree set the max depth 2 less than the depth it found above) on 10%, 30%, ... , 90% of the data. Compute the {term}`training accuracy` and test accuracy for each size training data in a DataFrame with columns ['train_pct','n_train_samples','n_test_samples','train_acc','test_acc'] | ||
| 1. Plot the accuracies vs training percentage in a line graph. | ||
| 1. Interpret these results. How does training vs test size impact the model? | ||
|
|
||
| _use a loop for this part, possibly also a function_ | ||
|
|
||
|
|
||
|
|
||
| ```{admonition} Thinking Ahead | ||
| _ideas for level 3_ | ||
| Repeat the problem setup experiment with cross validation and plot with error bars. | ||
| - What is the tradeoff to be made in choosing a test/train size? | ||
| - What is the best test/train size for this dataset? | ||
| or with variations: | ||
| - allowing it to figure out the model depth for each training size, and recording the depth in the loop as well. | ||
| - repeating each size 10 items, then using summary statistics on that data | ||
| Use the extensions above to experiment further with other model parameters. | ||
| **some of this we'll learn how to automate in a few weeks, but getting the | ||
| ideas by doing it yourself can help build understanding and intution** | ||
| ``` |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,252 @@ | ||
| --- | ||
| jupytext: | ||
| text_representation: | ||
| extension: .md | ||
| format_name: myst | ||
| format_version: 0.13 | ||
| jupytext_version: 1.14.1 | ||
| kernelspec: | ||
| display_name: Python 3 | ||
| language: python | ||
| name: python3 | ||
| --- | ||
|
|
||
| # Intro to ML & Naive Bayes | ||
|
|
||
|
|
||
|
|
||
| We're going to approach machine learning from the perspective of *modeling* for | ||
| a few reasons: | ||
| - model based machine learning streamlines understanding the big picture | ||
| - the model way of interpreting it aligns well with using sklearn | ||
| - thinking in terms of models aligns with incorporating domain expertise, as in our data science definition | ||
|
|
||
|
|
||
| this [paper](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/05/Bishop-MBML-2012.pdf) by Christopher M. Bishop, a pioneering ML researcher who also wrote one of a the widely preferred | ||
| graduate level ML textbooks, details advantages of a model based perspective and | ||
| a more mathematical version of a model based approach to machine learning. He is a co-author on an introductory [model based ML](https://mbmlbook.com/toc.html) | ||
|
|
||
|
|
||
|
|
||
| In CSC461: Machine Learning, you can encounter an *algorithm* focused approach | ||
| to machine learning, but I think having the model based perspective first helps | ||
| you avoid common pitfalls. | ||
|
|
||
|
|
||
|
|
||
| ## What is a Model? | ||
|
|
||
| A model is a simplified representation of some part of the world. A famous quote about models is: | ||
|
|
||
|
|
||
|
|
||
| All models are wrong, but some are useful | ||
| --[George Box](https://en.wikipedia.org/wiki/All_models_are_wrong)[^wiki] | ||
| --- | ||
|
|
||
| In machine learning, we use models, that are generally _statistical_ models. | ||
| --- | ||
| A statistical model is a mathematical model that embodies a set of statistical assumptions concerning the generation of sample data (and similar data from a larger population). A statistical model represents, often in considerably idealized form, the data-generating process | ||
| [wikipedia](https://en.wikipedia.org/wiki/Statistical_model#:~:text=A%20statistical%20model%20is%20a,%2C%20the%20data%2Dgenerating%20process.) | ||
|
|
||
| --- | ||
| read more in the[Model Based Machine Learning Book](http://www.mbmlbook.com/LearningSkills_A_model_is_a_set_of_assumptions.html) | ||
|
|
||
|
|
||
| ## Models in Machine Learning | ||
| --- | ||
| Starting from a dataset, we first make an additional designation about how we will use the different variables (columns). We will call most of them the _features_, which we denote mathematically with $\mathbf{X}$ and we'll choose one to be the _target_ or _labels_, denoted by $\mathbf{y}$. | ||
| --- | ||
| The core assumption for just about all machine learning is that there exists some function $f$ so that for the $i$th sample | ||
|
|
||
| $$ | ||
| y_i = f(\mathbf{x}_i) | ||
| $$ | ||
| --- | ||
| $i$ would be the index of a DataFrame | ||
| --- | ||
|
|
||
|
|
||
| --- | ||
| ## Types of Machine Learning | ||
|
|
||
| Then with different additional assumptions we get different types of machine learning: | ||
| - if both features ($\mathbf{X}$) and target ($\mathbf{y}$) are observed (contained in our dataset) it's [__supervised learning__](https://en.wikipedia.org/wiki/Supervised_learning) [code](https://scikit-learn.org/stable/supervised_learning.html) | ||
| - if only the features ($\mathbf{X}$) are observed, it's [__unsupervised learning__](https://en.wikipedia.org/wiki/Unsupervised_learning) [code](https://scikit-learn.org/stable/unsupervised_learning.html) | ||
|
|
||
| --- | ||
| ## Supervised Learning | ||
|
|
||
| we'll focus on supervised learning first. we can take that same core assumption and use it with additional information about our target variable to determine learning __task__ we are working to do. | ||
|
|
||
| $$ | ||
| y_i = f(\mathbf{x}_i) | ||
| $$ | ||
|
|
||
| - if $y_i$ are discrete (eg flower species) we are doing __classification__ | ||
| - if $y_i$ are continuous (eg height) we are doing __regression__ | ||
|
|
||
| --- | ||
| ## Machine Learning Pipeline | ||
|
|
||
| To do machine learning we start with __training data__ which we put as input to the __learning algorithm__. A learning algorithm might be a generic optimization procedure or a specialized procedure for a specific model. The learning algorithm outputs a trained __model__ or the parameters of the model. When we deploy a model we pair the __fit model__ with a __prediction algorithm__ or __decision__ algorithm to evaluate a new sample in the world. | ||
|
|
||
| In experimenting and design, we need __testing data__ to evaluate how well our learning algorithm understood the world. We need to use previously unseen data, because if we don't we can't tell if the prediction algorithm is using a rule that the learning algorithm produced or just looking up from a lookup table the result. This can be thought of like the difference between memorization and understanding. | ||
|
|
||
| When the model does well on the training data, but not on test data, we say that it does not generalize well. | ||
|
|
||
|  | ||
|
|
||
| ```{mermaid} | ||
| flowchart | ||
| data[[whole dataset]] | ||
| traindata[[training data]] | ||
| testdata[[test data]] | ||
| data-->|random split sample-wise|traindata | ||
| data-->|random split sample-wise|testdata | ||
| lalgo(learning algorithm) | ||
| traindata-->lalgo | ||
| lalgo-->palgo(prediction algorithm) | ||
| testdata -->palgo | ||
| pred[[predictions]] | ||
| palgo -->pred | ||
| metrics{scoring function} | ||
| pred -->metrics | ||
| testdata -->metrics | ||
| metrics-->score[[scores/ performance metrics]] | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| ## Let's Practice: | ||
|
|
||
| First machine learning model: Naive bayes | ||
| ```{code-cell} ipython3 | ||
| %matplotlib inline | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| import pandas as pd | ||
| import seaborn as sns | ||
| import numpy as np | ||
| from sklearn.model_selection import train_test_split | ||
| from sklearn.naive_bayes import GaussianNB | ||
| from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score | ||
| iris_df = sns.load_dataset('iris') | ||
| ``` | ||
| To start we will look at the data | ||
| ```{code-cell} ipython3 | ||
| iris_df.head(1) | ||
| ``` | ||
|
|
||
| And notice that there are equal number of samples for each value of the species. | ||
| ```{code-cell} ipython3 | ||
| iris_df['species'].value_counts() | ||
| ``` | ||
|
|
||
|  | ||
|
|
||
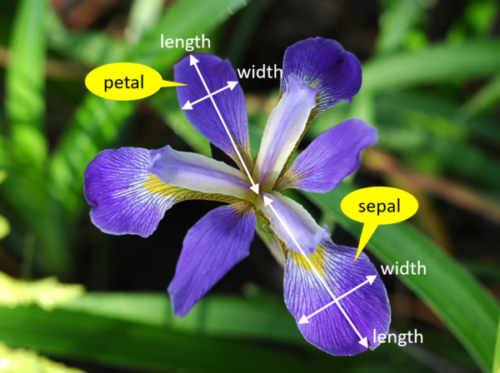
| We're trying to build an automatic flower classifier that, for measurements of a new flower returns the predicted species. To do this, we have a DataFrame with columns for species, petal width, petal length, sepal length, and sepal width. The species is what type of flower it is the petal and sepal are parts of the flower. | ||
|
|
||
| The species will be the target and the measurements will be the features. We want to predict the target from the features, the species from the measurements. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| feature_vars = ['sepal_length', 'sepal_width','petal_length', 'petal_width',] | ||
| target_var = 'species' | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| X_train, X_test, y_train, y_test = train_test_split(iris_df[feature_vars],iris_df[target_var],random_state=1) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| X_train.shape | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| X_test.shape | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| iris_df.shape | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| 112/150 | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.pairplot(iris_df,hue='species') | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| gnb = GaussianNB() | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| type(gnb) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| gnb.__dict__ | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| gnb.fit(X_train,y_train) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| gnb.__dict__ | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| gnb.score(X_test, y_test) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| y_pred = gnb.predict(X_test) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| y_pred[:3] | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| y_test[:3] | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| confusion_matrix(y_test,y_pred) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| print(classification_report(y_test,y_pred)) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sum(y_pred ==y_test) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| 37/len(y_test) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| y_train_pred = gnb.predict(X_train) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sum(y_train_pred == y_train) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| len(y_train) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| 106/112 | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| ``` |
Oops, something went wrong.