generated from rhodyprog4ds/syllabus_template
-
Notifications
You must be signed in to change notification settings - Fork 1
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
57698a2
commit c61e34c
Showing
3 changed files
with
331 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,329 @@ | ||
| --- | ||
| jupytext: | ||
| text_representation: | ||
| extension: .md | ||
| format_name: myst | ||
| format_version: 0.13 | ||
| jupytext_version: 1.14.1 | ||
| kernelspec: | ||
| display_name: Python 3 | ||
| language: python | ||
| name: python3 | ||
| --- | ||
|
|
||
| # Visualization | ||
|
|
||
| If your plots do not show, include this in any cell. The `%` signals that this is an | ||
| ipython [magic](https://ipython.readthedocs.io/en/stable/interactive/magics.html). This one controls [matplotlib](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-matplotlib). Jupyter uses the [IPython](https://ipython.readthedocs.io/en/stable/about/history.html) python kernel. | ||
| ```{code-cell} ipython3 | ||
| %matplotlib inline | ||
| ``` | ||
|
|
||
| Today's imports | ||
| ```{code-cell} ipython3 | ||
| import pandas as pd | ||
| import seaborn as sns | ||
| import matplotlib.pylab as plt | ||
| ``` | ||
|
|
||
| ## Summarizing Review | ||
| We will start with the same dataset we hvae been working with | ||
|
|
||
| ```{code-cell} ipython3 | ||
| robusta_data_url = 'https://raw.githubusercontent.com/jldbc/coffee-quality-database/master/data/robusta_data_cleaned.csv' | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| robusta_df = pd.read_csv(robusta_data_url) | ||
| ``` | ||
|
|
||
| Is the robust coffee's `Mouthfeel` or the `Aftertaste` more consistently scored in this dataset? | ||
|
|
||
|
|
||
| Why? | ||
|
|
||
| ```{code-cell} ipython3 | ||
| robusta_df[['Mouthfeel','Aftertaste']].describe() | ||
| ``` | ||
| from the lower `std` we can see that Aftertaste is more consistently rated. | ||
|
|
||
| We can also save this subset into a smaller dataframe to work with it more and plot it. | ||
| ```{code-cell} ipython3 | ||
| rob_ma_df = robusta_df[['Mouthfeel','Aftertaste']] | ||
| rob_ma_df.head(1) | ||
| ``` | ||
|
|
||
| We will use [`sns.displot`](https://seaborn.pydata.org/generated/seaborn.displot.html) to look at how the data is distributed. | ||
|
|
||
| ```{important} | ||
| For `seaborn` the online documentation is **immensely** valuable. Every function's page has basic documentation and lots of examples, so you can see how they use different paramters to modify plots visually. I **strongly recommend reading it often**. I recommend reading [their tutorial too](https://seaborn.pydata.org/tutorial/introduction.html) | ||
| ``` | ||
|
|
||
|
|
||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.displot(rob_ma_df) | ||
| ``` | ||
|
|
||
| We can change the kind, for example to a [Kernel Density Estimate](https://en.wikipedia.org/wiki/Kernel_density_estimation). | ||
| This approximates the distribution of the data, you can think of it rougly like | ||
| a smoothed out histogram. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.displot(rob_ma_df,kind='kde') | ||
| ``` | ||
| This version makess it more visually clear that the the Aftertaste is more consistently, but it also helps us see that that might not be the whole story. Both have a second smaller bump, so the overall std might not be the best measure. | ||
|
|
||
| ```{admonition} Question from class | ||
| Why do we need two sets of brackets? | ||
| ``` | ||
|
|
||
| It tries to use them to index in multiple ways instead. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| :tags: ["raises-exception"] | ||
| robusta_df['Aftertaste','Mouthfeel'] | ||
| ``` | ||
|
|
||
| It tries to look for a [multiindex](https://pandas.pydata.org/docs/user_guide/advanced.html#hierarchical-indexing-multiindex), but we do not have one so it fails. THe second square brackets, makes it a list of names to use and pandas looks for them sequentially. | ||
|
|
||
|
|
||
|
|
||
| We will use a larger dataset for more interesting plots. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| arabica_data_url = 'https://raw.githubusercontent.com/jldbc/coffee-quality-database/master/data/arabica_data_cleaned.csv' | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| coffee_df = pd.read_csv(arabica_data_url) | ||
| ``` | ||
| ## Plotting in Python | ||
|
|
||
| - [matplotlib](https://matplotlib.org/): low level plotting tools | ||
| - [seaborn](https://seaborn.pydata.org/index.html): high level plotting with opinionated defaults | ||
| - [ggplot](https://yhat.github.io/ggpy/): plotting based on the ggplot library in R. | ||
|
|
||
|
|
||
| Pandas and seaborn use matplotlib under the hood. | ||
|
|
||
| ````{margin} | ||
| ```{admonition} Think Ahead | ||
| Learning ggplot is a way to earn level 3 for visualize | ||
| ``` | ||
| ```` | ||
| Seaborn and ggplot both assume the data is set up as a DataFrame. | ||
| Getting started with seaborn is the simplest, so we'll use that. | ||
|
|
||
|
|
||
| There are lots of type of plots, we saw the basic patterns of how to use them and we've used a few types, but we cannot (and do not need to) go through every single type. There are general patterns that you can use that will help you think about what type of plot you might want and help you understand them to be able to customize plots. | ||
|
|
||
| [Seaborn's main goal is opinionated defaults and flexible customization](https://seaborn.pydata.org/tutorial/introduction.html#opinionated-defaults-and-flexible-customization | ||
|
|
||
| ### Anatomy of a figure | ||
|
|
||
| First is the [matplotlib](https://matplotlib.org) structure of a figure. BOth pandas and seaborn and other plotting libraries use matplotlib. Matplotlib was used [in visualizing the first Black hole](https://numfocus.org/case-studies/first-photograph-black-hole). | ||
|
|
||
| 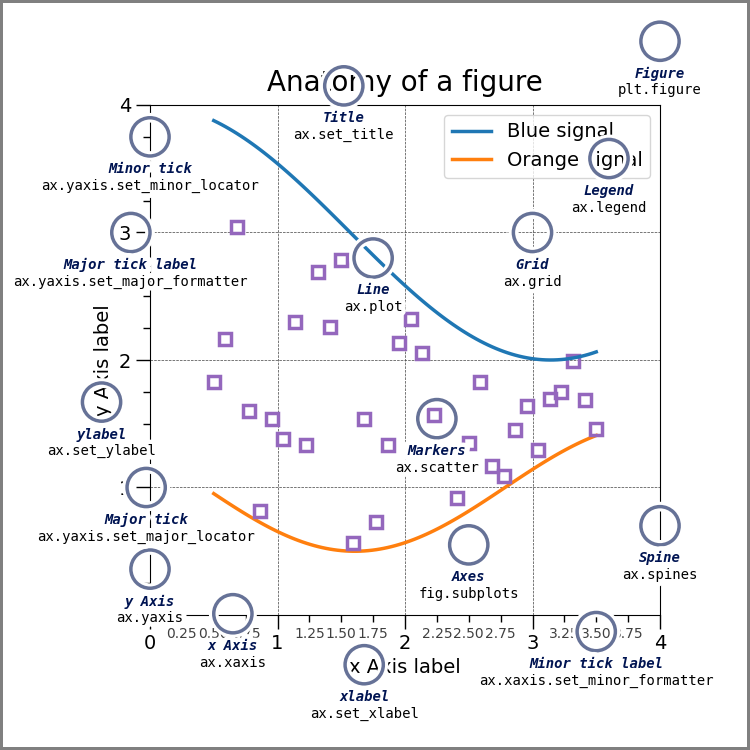 | ||
|
|
||
| This is a lot of information, but these are good to know things. THe most important is the figure and the axes. | ||
|
|
||
| ```{admonition} Try it Yourself | ||
| Make sure you can explain what is a figure and what are axes in your own words and why that distinction matters. Discuss in office hours if you are unsure. | ||
| ``` | ||
|
|
||
| *that image was [drawn with code](https://matplotlib.org/stable/gallery/showcase/anatomy.html#anatomy-of-a-figure)* and that page explains more. | ||
|
|
||
|
|
||
| ### Plotting Function types in Seaborn | ||
|
|
||
| Seaborn has two *levels* or groups of plotting functions. Figure and axes. Figure level fucntions can plot with subplots. | ||
|
|
||
| 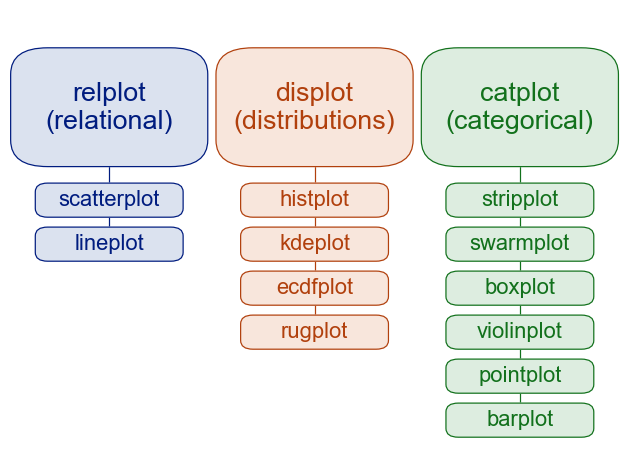 | ||
|
|
||
|
|
||
| This is from thie [overivew]() section of the official seaborn tutorial. It also includes a comparison of | ||
| [figure vs axes](https://seaborn.pydata.org/tutorial/function_overview.html#relative-merits-of-figure-level-functions) plotting. | ||
|
|
||
| The [official introduction](https://seaborn.pydata.org/tutorial/introduction.html) is also a good read. | ||
|
|
||
| ### More | ||
|
|
||
| The [seaborn gallery](https://seaborn.pydata.org/examples/index.html) and [matplotlib gallery](https://matplotlib.org/2.0.2/gallery.html) are nice to look at too. | ||
|
|
||
| +++ | ||
|
|
||
|
|
||
| ### Styling in Seaborn | ||
| Seaborn also lets us set a theme for visual styling | ||
| This by default styles the plots to be more visually appealing | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.set_theme(palette='colorblind') | ||
| ``` | ||
|
|
||
| the colorblind palette is more distinguishable under a variety fo colorblindness types. [for more](https://gist.github.com/mwaskom/b35f6ebc2d4b340b4f64a4e28e778486). | ||
| Colorblind is a good default, but you can choose others that you like more too. | ||
|
|
||
| [more on colors](https://seaborn.pydata.org/tutorial/color_palettes.html#general-principles-for-using-color-in-plots) | ||
|
|
||
|
|
||
| ## Bags by country | ||
|
|
||
| the `catplot` lets us plot vs categorical variables. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.catplot(data=coffee_df, y='Number.of.Bags',x='Country.of.Origin') | ||
| ``` | ||
| This is hard to read, we could try stretching it out to make it better | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.catplot(data=coffee_df, y='Number.of.Bags',x='Country.of.Origin',aspect=2) | ||
| ``` | ||
|
|
||
| A better way might be to filter only the top countries. We'll find those by grouping by country | ||
| then summing each smaller dataframe that groupby creates. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| tot_per_country = coffee_df.groupby('Country.of.Origin')['Number.of.Bags'].sum() | ||
| tot_per_country.head() | ||
| ``` | ||
| We can plot this now this way | ||
| ```{code-cell} ipython3 | ||
| tot_per_country.plot(kind='bar') | ||
| ``` | ||
|
|
||
| What if we take out only the top 10 countries? First we have to sort it. The default | ||
| is to sort ascending so we use `ascending=False` to switch. pandas doesn'thave a plain `sort` | ||
| method, we have to say if we want to sort by the values or the index. In this Series, the | ||
| total number per for each country are the values and the country names are the index. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| tot_per_country.sort_values(ascending=False)[:10] | ||
| ``` | ||
| We can alo plot this | ||
|
|
||
| ```{code-cell} ipython3 | ||
| tot_per_country.sort_values(ascending=False)[:10].plot(kind='bar') | ||
| ``` | ||
|
|
||
| ## Filtering a DataFrame | ||
| Now, we'll take just the country names out | ||
|
|
||
| ```{code-cell} ipython3 | ||
| top_countries = tot_per_country.sort_values(ascending=False)[:10].index | ||
| top_countries | ||
| ``` | ||
|
|
||
| and we can use that to filter the original `DataFrame`. To do this, we use [`isin`](https://pandas.pydata.org/docs/reference/api/pandas.Series.isin.html#pandas.Series.isin) to check each element in the `'Country.of.Origin'` column is in that list. | ||
|
|
||
| ```{code-cell} ipython3 | ||
| coffee_df['Country.of.Origin'].isin(top_countries) | ||
| ``` | ||
|
|
||
| This is roughly equivalent to: | ||
| ```{code-cell} ipython3 | ||
| [country in top_countries for country in coffee_df['Country.of.Origin'] ] | ||
| ``` | ||
| except this builds a list and the pandas way makes a `pd.Series` object. The Python [`in` operator](https://docs.python.org/3/reference/expressions.html#in) is really helpful to know and pandas offers us an `isin` method to get that type of pattern. | ||
|
|
||
| In a more basic programming format this process would be two separate loops worth of work. | ||
| ```{code-cell} ipython3 | ||
| c_in = [] | ||
| # iterate over the country of each rating | ||
| for country in coffee_df['Country.of.Origin']: | ||
| # make a false temp value | ||
| cur_search = False | ||
| # iterate over top countries | ||
| for tc in top_countries: | ||
| # flip the value if the current top & rating cofee match | ||
| if tc==country: | ||
| cur_search = True | ||
| # save the result of the search | ||
| c_in.append(cur_search) | ||
| ``` | ||
|
|
||
| ```{admonition} Try it yourself | ||
| Run these versions and confirm for yourself that they are the same. | ||
| ``` | ||
|
|
||
| With that list of booleans, we can then [mask the original DataFrame](https://pandas.pydata.org/docs/user_guide/indexing.html#boolean-indexing). This keeps only the value where the inner quantity is `True` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| top_coffee_df = coffee_df[coffee_df['Country.of.Origin'].isin(top_countries)] | ||
| top_coffee_df.head(1) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| top_coffee_df.shape, coffee_df.shape | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| sns.displot(data=top_coffee_df,x='Aftertaste', col='Country.of.Origin',col_wrap=5) | ||
| ``` | ||
|
|
||
| ```{code-cell} ipython3 | ||
| ``` | ||
|
|
||
|
|
||
| ## Variable types and data types | ||
|
|
||
| Related but not the same. | ||
|
|
||
| --- | ||
|
|
||
| Data types are literal, related to the representation in the computer. | ||
|
|
||
| ther can be `int16, int32, int64` | ||
|
|
||
| --- | ||
|
|
||
| We can also have mathematical types of numbers | ||
|
|
||
| - Integers can be positive, 0, or negative. | ||
| - Reals are continuous, infinite possibilities. | ||
| --- | ||
|
|
||
|
|
||
| Variable types are about the meaning in a conceptual sense. | ||
|
|
||
| - **categorical** (can take a discrete number of values, could be used to group data, | ||
| could be a string or integer; unordered) | ||
| - **continuous** (can take on any possible value, always a number) | ||
| - **binary** (like data type boolean, but could be represented as yes/no, true/false, | ||
| or 1/0, could be categorical also, but often makes sense to calculate rates) | ||
| - **ordinal** (ordered, but appropriately categorical) | ||
|
|
||
| we'll focus on the first two most of the time. Some values that are technically | ||
| only integers range high enough that we treat them more like continuous most of | ||
| the time. | ||
|
|
||
| ## Questions After Class | ||
|
|
||
| ### Do we earn level 3's the same way level 1 and 2 are or are there more steps required? | ||
|
|
||
| You earn level 3s from your portfio. The portfolio makes more sense after you have completed assignment 3, so we will follow up on it next week after you all get a3 feedback. | ||
|
|
||
| ### How can I check what parameters can go into a method? | ||
| You can use the documentation online, or in jupyter, you can get help from the docstring. I usually use shift+tab to read the docstring but you can also use the `help()` function or the `?` in jupyter. | ||
|
|
||
| ### How do you know you can put kind = "bar" into the method? | ||
| I happen to reembmer this now, but to know what values you can read the docstring as above. | ||
|
|
||
| ### Do companies use things like "sns" for more in depth/graphical plots? | ||
|
|
||
| It depends on your role within the company. If you are a data scientist in a more reasearch role you might use seaborn more, but if you build customer facing visualizations, you might use something else. | ||
|
|
||
| For more interactive visualization, you could use [plotly](https://plotly.com/python/) or [bokeh](https://docs.bokeh.org/en/latest/) that generate more javascript for you. [Plotly](https://plotly.com/) as a company now also has a product called [dash](https://dash.plotly.com/) for building data dashboard apps. | ||
|
|
||
|
|
||
|
|
||
| ### Does "component disciplines" mean statistics, computer science and domain expertise,, and does "phases" mean collect, clean, explore, model and deploy? | ||
|
|
||
| Yes. | ||
|
|
||
| ```{important} | ||
| I updated the assignment text to clarify in response to some questions | ||
| ``` |