{kind=link}
- This project implements REST API's in Spring-boot.
- The API endpoints print out GTFS data.
- The GTFS data is stored in Graphic Database NEO4j which is running on localhost.
- The GTFS data is for Hamburg city, from October,17 till November,17
- GTFS zip file is also commited in the code with the name
gtfs-hamburg.zip
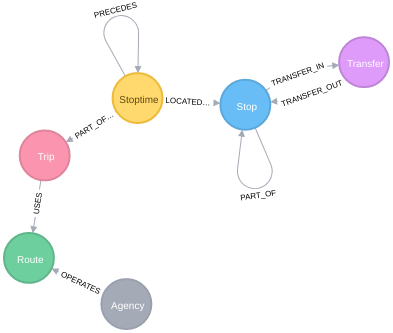
Our Neo4j Database Schema is as follows:
Following queries are used to populate the Database:
create constraint on (a:Agency) assert a.id is unique;
create constraint on (r:Route) assert r.id is unique;
create constraint on (t:Trip) assert t.id is unique;
create index on :Trip(service_id);
create constraint on (s:Stop) assert s.id is unique;
create index on :Stoptime(stop_sequence);
create index on :Stop(name);
- Add Agency:
load csv with headers from
'file:///hamburg/agency.txt' as csv
create (a:Agency {id: toInt(csv.agency_id), name: csv.agency_name});
- Add Routes
load csv with headers from
'file:///ns/routes.txt' as csv
match (a:Agency {id: toInt(csv.agency_id)})
create (a)-[:OPERATES]->(r:Route {id: csv.route_id, short_name: csv.route_short_name, long_name: csv.route_long_name, type: toInt(csv.route_type)});
- Add Trips
load csv with headers from
'file:///hamburg/trips.txt' as csv
match (r:Route {id: csv.route_id})
create (r)<-[:USES]-(t:Trip {id: csv.trip_id, service_id: csv.service_id, headsign: csv.trip_headsign, direction_id: csv.direction_id, short_name: csv.trip_short_name});
- Add Stops
load csv with headers from
'file:///hamburg/stops.txt' as csv
create (s:Stop {id: csv.stop_id, name: csv.stop_name, lat: toFloat(csv.stop_lat), lon: toFloat(csv.stop_lon), platform_code: csv.platform_code, parent_station: csv.parent_station, location_type: csv.location_type, code: csv.stop_code});
- Add Parent Child relationship between Stops
load csv with headers from
'file:///hamburg/stops.txt' as csv
with csv
where not (csv.parent_station is null)
match (ps:Stop {id: csv.parent_station}), (s:Stop {id: csv.stop_id})
create (ps)<-[:PART_OF]-(s);
- Add Stoptimes (File is around 76 MB so use periodic commit)
using periodic commit
load csv with headers from
'file:///hamburg/stop_times.txt' as csv
create (st:Stoptime {arrival_time: csv.arrival_time, departure_time: csv.departure_time, stop_sequence: toInt(csv.stop_sequence), tripId: csv.trip_id, stopID: csv.stop_id});
- Connect Trip to Stoptime
match (st:Stoptime), (t:Trip)
where st.tripId = t.id
create (t)<-[:PART_OF_TRIP]-(st)
- Connect Stop to Stoptime
match (st:Stoptime), (s:Stop)
where st.stopId = s.id
create (st)-[:LOCATED_AT]->(s)
- Connect the stoptime sequences
match (s1:Stoptime)-[:PART_OF_TRIP]->(t:Trip),
(s2:Stoptime)-[:PART_OF_TRIP]->(t)
where s2.stop_sequence=s1.stop_sequence+1
create (s1)-[:PRECEDES]->(s2);
- Create Transfers
load csv with headers from
'file:///hamburg/transfers.txt' as csv
create (t:Transfer {fromStop: csv.from_stop_id, toStop: csv.to_stop_id, transferType: csv.transfer_type, minTransferTime: csv.min_transfer_time, fromRoute:csv.from_route_id, toRoute: csv.to_route_id });
- Connect Stops with Transfers
match(s:Stop), (t:Transfer)
where t.fromStop = s.id
create (s)-[:TRANSFER_IN]->(t)
match(s:Stop), (t:Transfer)
where t.toStop = s.id
create (t)-[:TRANSFER_OUT]->(s)